ANOVA Test (R)
इस पोस्ट में, मैं Anova hypothesis testing पर ध्यान देना चाहता हूँ। डेटा-सेट जो मैं उपयोग करने जा रहा हूँ, वह https://smartcities.data.gov.in पर प्रकाशित है, जो कि भारत सरकार का एक प्रोजेक्ट है जो National Data Sharing and Accessibility Policy के तहत आता है।
मैं यह विश्लेषण करना चाहता हूँ कि क्या बैंगलोर में बेरोजगारी समान है या क्या कुछ क्षेत्रों में उच्च बेरोजगारी है। Unemployment_Rate_Bengaluru.csv डेटा सेट में बैंगलोर में वार्ड स्तर पर कुल रोजगार और बेरोजगार लोगों की जानकारी है। सरलता के लिए, मैं तीन क्षेत्रों पर ध्यान केंद्रित करना चाहता हूँ: बैंगलोर-पूर्व, महादेवपुरा और राजेश्वरी नगर।
चूंकि मैं यह परीक्षण करना चाहता हूँ कि बैंगलोर के विभिन्न क्षेत्रों में बेरोजगारी दर में महत्वपूर्ण अंतर है या नहीं, शून्य और वैकल्पिक परिकल्पना इस प्रकार होगी:
$$ H_0: \mu_{Bangalore-east} = \mu_{Mahadevpura} = \mu_{Rajeshwari-Nagar} $$
$$ H_1: Not\, all\, \mu\, are\, equal $$
नमूना बेरोजगारी डेटा सेट:
| cityName | zoneName | wardName | wardNo | unemployed.no | employed.no | total.labour | rate |
|---|---|---|---|---|---|---|---|
| Bengaluru | East | Manorayana Palya | 167 | 19011 | 13745 | 32756 | 0.5803822 |
| Bengaluru | East | Ganga Nagar | 154 | 18294 | 14346 | 32640 | 0.5604779 |
| Bengaluru | Mahadevapura | Basavanapura | 187 | 27146 | 22061 | 49207 | 0.5516695 |
| Bengaluru | Mahadevapura | Ramamurthy Nagar | 26 | 27085 | 20273 | 47358 | 0.5719203 |
| Bengaluru | East | Radhakrishna Temple Ward | 18 | 20081 | 15041 | 35122 | 0.5717499 |
प्रत्येक क्षेत्र में बेरोजगारी के अंतर को विज़ुअलाइज़ करना।
ggplot(unemployment, aes(x=zoneName, y= rate, group = zoneName)) +
geom_boxplot() +
labs(x='Zone', y='Unemployment %') +
theme_minimal()
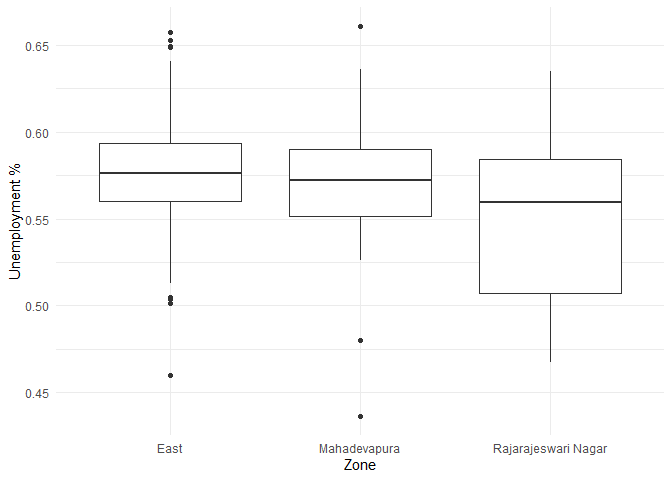
विभिन्न क्षेत्रों में बेरोजगारी के सारांश सांख्यिकी इस प्रकार हैं:
data.summary <- unemployment %>%
rename(group = zoneName) %>%
group_by(group) %>%
summarise(count = n(),
mean = mean(rate),
sd = sd(rate),
skewness = skewness(rate),
kurtosis = kurtosis(rate))
data.summary
## # A tibble: 3 x 6
## group count mean sd skewness kurtosis
## <chr> <int> <dbl> <dbl> <dbl> <dbl>
## 1 East 81 0.574 0.0361 -0.228 0.747
## 2 Mahadevapura 24 0.567 0.0449 -0.812 1.69
## 3 Rajarajeswari Nagar 18 0.548 0.0499 0.00421 -1.24
उपरोक्त तालिका से मैं देखता हूँ कि बेरोजगारी दर सभी तीन क्षेत्रों में 54% से 57% के बीच है।
ANOVA करने की एक शर्त यह है कि जनसंख्या प्रतिक्रिया चर प्रत्येक समूह में सामान्य वितरण का पालन करता है। विभिन्न क्षेत्रों में बेरोजगारी दर का वितरण इस प्रकार है:
ggplot() +
geom_density(data=unemployment, aes(x=rate, group=zoneName, color=zoneName), adjust=2) +
labs(x = 'Unemployment Rate', y='Density', title = 'Testing normality among response variables') +
theme_minimal()+theme(legend.position="bottom")
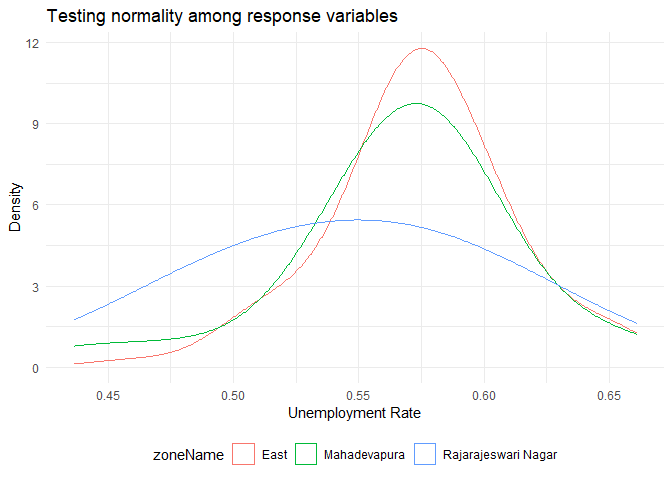
उपरोक्त ग्राफ से, ऐसा लगता है कि तीन समूह सामान्य रूप से वितरित हैं। सामान्यता के लिए परीक्षण करने के लिए, हम Shapiro-Wilk परीक्षण का उपयोग कर सकते हैं।
प्रत्येक समूह के लिए परीक्षण की परिकल्पना इस प्रकार होगी:
\(H_0\): समूह में बेरोजगारी दर सामान्य रूप से वितरित है
\(H_1\): समूह में बेरोजगारी दर सामान्य रूप से वितरित नहीं है
for(i in 1:nrow(data.summary)){
test.dist <- (unemployment %>% dplyr::filter(zoneName == data.summary$group[i]))$rate
cat('Testing for group ', data.summary$group[i], '\n')
print(shapiro.test(test.dist))
norm.plot <- ggplot() +
geom_qq(aes(sample = test.dist)) +
stat_qq_line(aes(sample = test.dist)) +
ggtitle(paste0("Normal distribution Q-Q plot for group ",data.summary$group[i])) +
theme_minimal()
plot(norm.plot)
}
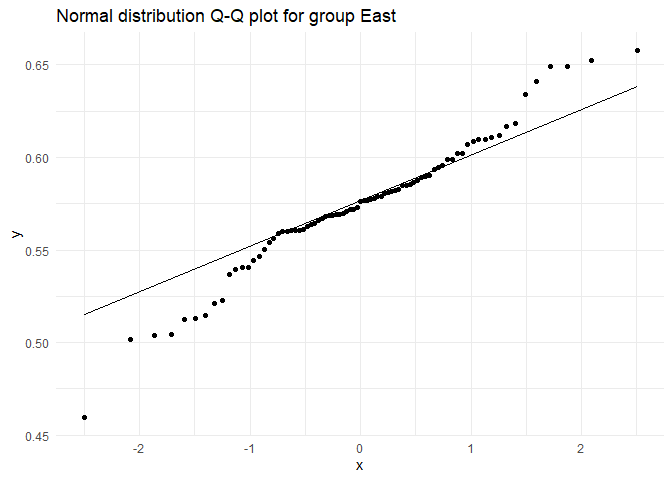
## Testing for group East
##
## Shapiro-Wilk normality test
##
## data: test.dist
## W = 0.97147, p-value = 0.06734
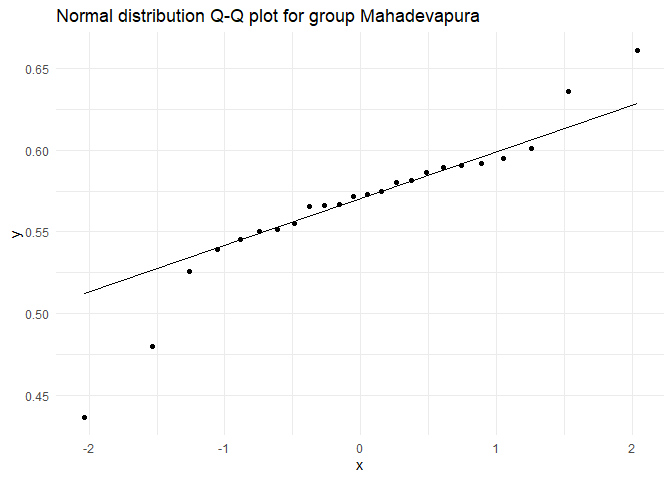
## Testing for group Mahadevapura
##
## Shapiro-Wilk normality test
##
## data: test.dist
## W = 0.90815, p-value = 0.03216
## Testing for group Rajarajeswari Nagar
##
## Shapiro-Wilk normality test
##
## data: test.dist
## W = 0.95852, p-value = 0.5734
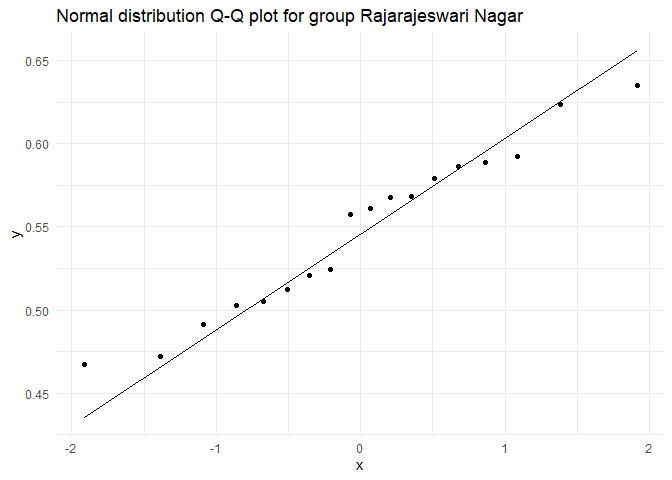
चूंकि \(p > \alpha\), जहाँ \(\alpha = 0.01\), सभी तीन समूहों में शून्य परिकल्पना को बनाए रखा जा रहा है। इसलिए, हम मान सकते हैं कि सभी समूहों में बेरोजगारी दर सामान्य रूप से वितरित है।
ANOVA के लिए एक और शर्त यह है कि जनसंख्या के विविधताओं को समान माना जाता है। यह एक अनुमान है जिसे मैं इस समय लेना चाहता हूँ।
इन अनुमानों को लेते हुए, नमूने के आदर्श वितरण इस प्रकार हैं। इन वितरणों की तुलना एक simulation से की जा सकती है जिसे मैंने बनाया है, जहाँ F मान (और ANOVA की महत्वता) को समूह के औसत के बीच की दूरी बढ़ाकर देखा जा सकता है।
plot.normal.groups <- function(data.summary, mean, sd, label, title){
common.group.sd <- mean(data.summary$sd)
range <- seq(mean-3*sd, mean+3*sd, by = sd*0.001)
norm.dist <- data.frame(range = range, dist = dnorm(x = range, mean = mean, sd = sd))
# Plotting sampling distribution and x_bar value with cutoff
norm.aov.plot <- ggplot(data = norm.dist, aes(x = range,y = dist))
for (i in 1:nrow(data.summary)) {
norm.aov.plot <- norm.aov.plot +
stat_function(fun = dnorm, color=colors()[sample(50:100, 1)], size = 1,
args = list(mean = data.summary$mean[i], sd = common.group.sd))
}
norm.aov.plot + labs(x = label, y='Density', title = title) +
theme_minimal()+theme(legend.position="bottom")
}
set.seed(9)
mean <- mean(unemployment$rate)
sd <- sd(unemployment$rate)
plot.normal.groups(data.summary, mean, sd, 'Travel time (sec)', 'Assuming normality among response variables')
ANOVA करने के लिए
$$ H_0: \mu_{Bangalore-east} = \mu_{Mahadevpura} = \mu_{Rajeshwari-Nagar} $$
$$ H_1: Not\, all\, \mu\, are\, equal $$
# Functions used in anova-test
f.plot <- function(pop.mean=0, alpha = 0.05, f, df1, df2,
label = 'F distribution',title = 'Anova test'){
# Creating a sample F distribution
range <- seq(qf(0.0001, df1, df2), qf(0.9999, df1, df2), by = (qf(0.9999, df1, df2)-qf(0.0001, df1, df2))*0.001)
f.dist <- data.frame(range = range, dist = df(x = range, ncp = pop.mean, df1 = df1, df2 = df2)) %>%
dplyr::mutate(H0 = if_else(range <= qf(p = 1-alpha, ncp = pop.mean, df1 = df1,df2 = df2),'Retain', 'Reject'))
# Plotting sampling distribution and F value with cutoff
plot.test <- ggplot(data = f.dist, aes(x = range,y = dist)) +
geom_area(aes(fill = H0)) +
scale_color_manual(drop = TRUE, values = c('Retain' = "#00BFC4", 'Reject' = "#F8766D"), aesthetics = 'fill') +
geom_vline(xintercept = f, size = 2) +
geom_text(aes(x = f, label = paste0('F = ', round(f,3)), y = mean(dist)), colour="blue", vjust = 1.2) +
labs(x = label, y='Density', title = title) +
theme_minimal()+theme(legend.position="bottom")
plot(plot.test)
}
anva <- aov(rate ~ zoneName, unemployment)
anova.summary <- summary(anva)
print(anova.summary)
## Df Sum Sq Mean Sq F value Pr(>F)
## zoneName 2 0.01065 0.005323 3.315 0.0397 *
## Residuals 120 0.19269 0.001606
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
f.plot(f = anova.summary[[1]]$F[1], df1 = anova.summary[[1]]$Df[1], df2 = anova.summary[[1]]$Df[2])
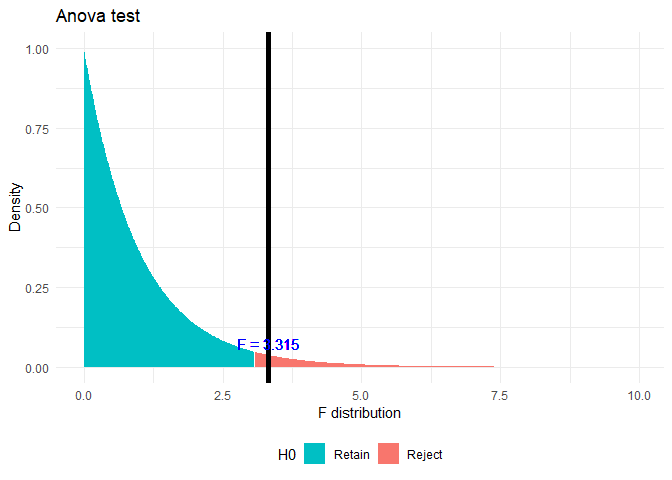
यहाँ \(p < \alpha\), जहाँ \(\alpha = 0.05\) इसलिए शून्य परिकल्पना को अस्वीकार किया जा रहा है। इस परीक्षण से हम देख सकते हैं कि सभी समूहों का औसत समान नहीं है। लेकिन यह जानने के लिए कि कौन से समूह समान हैं और कौन से भिन्न हैं, मैं TukeyHSD परीक्षण कर रहा हूँ।
tukey.test <- TukeyHSD(anva)
print(tukey.test)
## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = rate ~ zoneName, data = unemployment)
##
## $zoneName
## diff lwr upr
## Mahadevapura-East -0.007071899 -0.02917267 0.015028872
## Rajarajeswari Nagar-East -0.026768634 -0.05154855 -0.001988723
## Rajarajeswari Nagar-Mahadevapura -0.019696735 -0.04934803 0.009954561
## p adj
## Mahadevapura-East 0.7285538
## Rajarajeswari Nagar-East 0.0309193
## Rajarajeswari Nagar-Mahadevapura 0.2597730
# Plot pairwise TukeyHSD comparisons and color by significance level
tukey.df <- as.data.frame(tukey.test$zoneName)
tukey.df$pair = rownames(tukey.df)
ggplot(tukey.df, aes(colour=cut(`p adj`, c(0, 0.01, 0.05, 1),
label=c("p<0.01","p<0.05","Non-Sig")))) +
geom_hline(yintercept=0, lty="11", colour="grey30") +
geom_errorbar(aes(pair, ymin=lwr, ymax=upr), width=0.2) +
geom_point(aes(pair, diff)) +
labs(x = 'Groups', y='Density', colour="", title = 'Tukey HSD Test') +
theme_minimal()+theme(legend.position="bottom")
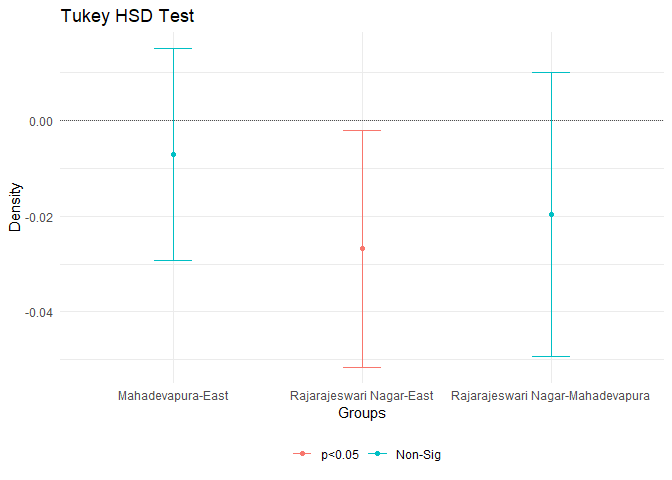
इस परीक्षण से हम देख सकते हैं कि राजेश्वरी नगर और बैंगलोर पूर्व के बीच महत्वपूर्ण अंतर है (जिसका \(\alpha = 0.05\) विश्वास स्तर है)।