Probability (R)
Probability क्यों महत्वपूर्ण है¶
Data science के मूलभूत विषयों में से एक probability है। इसका कारण यह है कि असली दुनिया में, हमेशा ऐसे random effects होते हैं जो सबसे predictable events में भी randomness पैदा करते हैं। Randomness हमारे दैनिक जीवन में, अनुसंधान से लेकर व्यापारिक अनुप्रयोगों तक, हर जगह पाया जाता है। Probability एक ऐसा क्षेत्र है जो हमें uncertainty के खिलाफ लड़ने के लिए उपकरण प्रदान करता है और इसलिए यह statistics, econometrics, game theory और machine learning की backbone है।
Probabilistic model के तत्व¶
चलो एक experiment लेते हैं जहाँ संभावित परिणाम हैं \(\omega_1, \omega_2,...\)।
उदाहरण के लिए, अगर हम एक six-sided die फेंकते हैं, तो परिणाम हैं \(\omega_1 = 1, \omega_2 = 2, \omega_3 = 3, \omega_4 = 4, \omega_5 = 5, \omega_6 = 6\)। सभी परिणामों का यह सेट sample space कहलाता है और इसे \(\Omega\) से दर्शाया जाता है। Sample space का एक subset event कहलाता है। उदाहरण के लिए, six-headed die roll में 3 या 4 आना एक event है।
Probability के नियम¶
कौन सा event होने की संभावना अधिक है और कौन सा कम है। इसे probability function P(A) का उपयोग करके समझाया जाता है। Probability के चार नियम हैं:
1. \(0 \leq P(A) \leq 1\): किसी event की probability 0 और 100% के बीच होती है।
2. \(P(\Omega) = 1\): sample space की probability 1 होती है।
3. यदि event A और event B disjoint हैं, तो \(P(A \cup B) = P(A) + P(B)\)।
4. यदि events \(A_i\) pairwise disjoint events हैं, अर्थात् \(A_i \cap A_j = \phi\), तो \(P(\cup_{i=1}^{\infty}A_i) = \sum_{i=0}^\infty P(A_i)\)।
कोई भी probability function जो इन तीन axioms को संतुष्ट करता है, उसे एक valid probability function माना जाता है।
इन axioms से निकाली जा सकने वाली कुछ properties हैं:
1. \(P(A^C) = 1-P(A)\)
2. \(P(A \cap B) = P(A) + P(B) - P(A \cup B)\)
3. यदि \(A \subset B\) है तो \(P(A) \leq P(B)\)
4. यदि \(P(A \cap B) = P(A)P(B)\), तो A और B स्वतंत्र हैं।
Conditional probability¶
मान लीजिए A और B एक ही sample space से दो events हैं। B के दिए जाने पर A की conditional probability यह है कि A होने की संभावना है यदि B पहले ही हो चुका है। इसे इस प्रकार दिया जाता है:
\(P(A|B) = \frac{P(A \cap B)}{P(B)}\)
उपरोक्त से, हम निम्नलिखित प्राप्त कर सकते हैं:
1. \(P(A \cap B) = P(B)\times P(A|B) = P(A)\times P(B|A)\)
2. \(P(A) = \sum_{i=1}^n P(A|B_i)\times P(B_i)\) जहाँ \(B_i\) sample space का एक partition बनाते हैं। इसे total probability का formula कहा जाता है।
Bayes theorem¶
यदि A और B दो events हैं जहाँ P(A)>0, तो
\(P(A | B) = \frac{P(B|A)P(A)}{\sum_{i=1}^n P(B|A_i)\times P(A_i)}\)
जहाँ \(A_j\) sample space का एक partition बनाते हैं \(\cup_{i=1}^{\infty}A_i = \Omega\) और \(i\neq j, A_i \neq A_j\)।
Random Variables¶
Random variables हमें probability distributions को समझने में मदद करते हैं। एक random variable experiment के outcomes को sample space से एक numerical quantity में map करता है। उदाहरण के लिए, अगर हम एक coin को चार बार flip करते हैं, तो हमें निम्नलिखित outcomes मिल सकते हैं, H के लिए heads और T के लिए tails: HTHT, HHTT, HHHT, TTTH, TTTT आदि। यदि हम एक variable लेते हैं जो series में heads की संख्या को मापता है, तो हमें mapping मिलेगी: HTHT - 2; HHTT - 2; HHHT - 3; TTTH - 1; TTTT - 0 और इसी तरह। Random variable की randomness event से जुड़ी होती है, experiment से नहीं। Random variables यही mapping हैं जो experiment के outcomes को numerical quantities में map करते हैं। Random variables के दो प्रकार होते हैं, discrete और continuous random variables।
Discrete random variable की range में finite या countably infinite values की sequence होती है। कुछ उदाहरण हैं:
1. 10 coin flips में heads की संख्या: finite
2. जब तक heads नहीं आते, coin के flips की संख्या: countable infinite
Continuous random variables की range एक interval होती है जो real numbers में finite या infinite हो सकती है। एक उदाहरण होगा कि अगला customer store में आने तक का समय।
Distribution functions¶
Distribution functions का उपयोग random variables के व्यवहार को characterize करने के लिए किया जाता है, जैसे mean, standard deviation और probabilities। Distribution functions के दो प्रकार होते हैं, probability distribution functions और cumulative distribution functions।
Discrete random variables के लिए, हम probability mass function का उपयोग करते हैं, जो यह probability है कि एक random variable एक specific value लेगा। Continuous random variables के लिए, किसी interval में random variable की probability probability density function को integrate करके प्राप्त की जाती है।
cumulative distribution functions दर्शाती हैं कि variable उस range से कम या उसके बराबर value लेगा।
दो random variables \(Y_1\) और \(Y_2\) को एक-दूसरे से स्वतंत्र कहा जाता है यदि \(P(Y_1 \in A, Y_2 \in B) = P(Y_1 \in A)\times P(Y_2 \in B)\)।
Discrete random variables¶
Discrete random variables के लिए, PMF और CDF को इस प्रकार परिभाषित किया गया है:
$$ PMF = p_X(x) := P(X = x) $$
$$ CMF = F_X(x) := P(X\leq x) $$
Discrete random variables का mean और variance
मान लीजिए X एक random variable है जिसकी range {\(x_1, x_2, ...\)} है। एक random variable का mean और variance इस प्रकार दिया जाता है:
Expected value (Mean): \(E[X] := \sum_{i=1}^n x_i \times P(X=x_i)\)
Variance: \(Var(X) := E[(X-E[X])^2] = E[X^2]-E[X]^2\)
Standard Deviation \(SD(X) = \sqrt{Var(X)}\)
यदि दो events X और Y स्वतंत्र हैं, तो
1. E[XY] = E[X]E[Y]
2. \(Var(aX+bY) = a^2Var(X) + b^2 Var(Y)\)
Bernoulli distribution¶
कल्पना कीजिए एक experiment जिसमें दो outcomes हो सकते हैं, success या failure लेकिन दोनों नहीं। हम ऐसे experiment को Bernoulli trial कहते हैं। मान लीजिए random variable X है, जो success होने पर 1 और failure होने पर 0 assign करता है। यदि success की probability 'p' है, तो Probability mass function इस प्रकार दिया जाता है:
\(P(X=x)=\left\{ \begin{array}{ll} p \qquad x=1\\ 1-p \quad x=0 \end{array} \right.\)
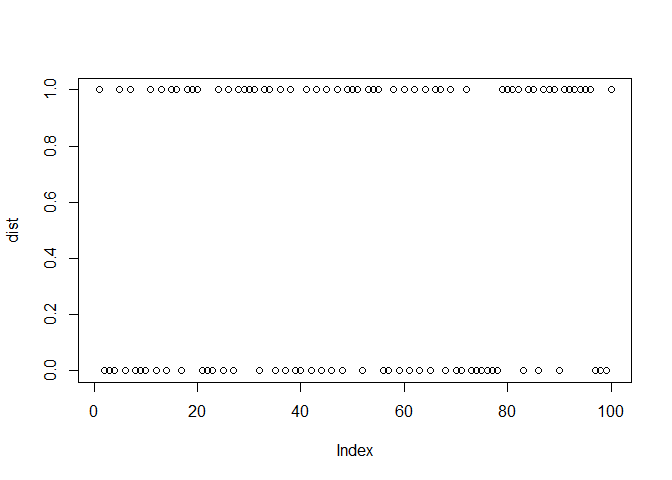
कल्पना कीजिए कि एक coin को flip किया जाता है जिसमें heads की probability 60% (success की probability) है, 100 बार। नीचे इसका simulation दिया गया है:
dist <- rbinom(100, 1, 0.6)
plot(dist)
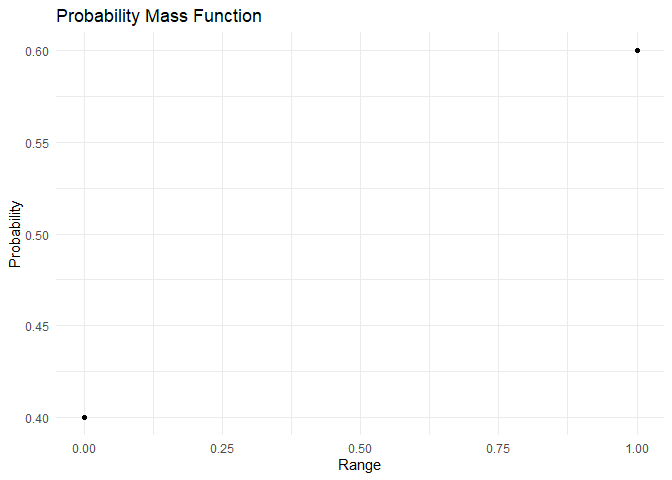
Bernoulli distribution का PMF और CDF इस प्रकार हैं:
range <- c(0,1)
pmf <- dbinom(x=range, size = 1,prob = 0.6)
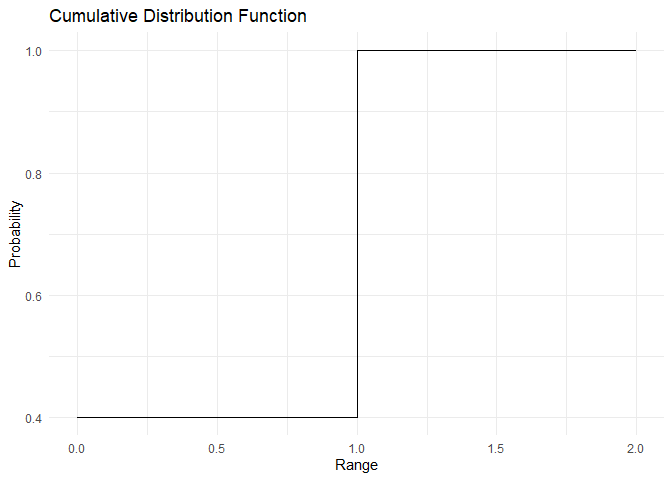
cdf <- pbinom(q = range, size = 1, prob = 0.6)
plot_pmf(pmf,range)
plot_cdf(cdf, range)
Bernoulli distribution का mean और variance \(E[X] = p\) और \(Var(X) = p\times q\) है। इसे नीचे दिए गए code का उपयोग करके सत्यापित किया जा सकता है:
mean(dist)
## [1] 0.54
var(dist)
## [1] 0.2509091
Binomial distribution¶
कल्पना कीजिए एक experiment जिसमें हम स्वतंत्र Bernoulli trials को n बार दोहरा रहे हैं। तब हम इस distribution को केवल दो parameters, success probability p और trials की संख्या n का उपयोग करके characterize कर सकते हैं। यदि हमारे पास n trials में r successes हैं, तो हम उस event के होने की probability को binomial distribution का उपयोग करके दर्शाते हैं। Binomial distribution का PMF इस प्रकार दिया जाता है:
\(P(X=x)=(^nc_r)\times p^r\times q^{n-r}\)
एक binomial random variable n Bernoulli distributions का योग होता है।
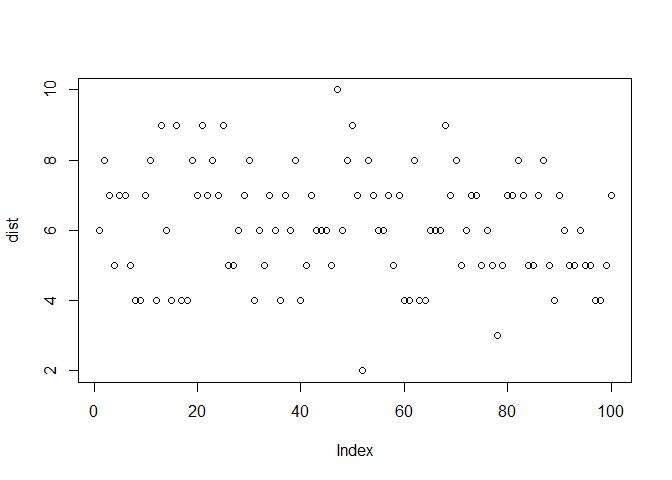
कल्पना कीजिए कि एक coin को 10 बार flip किया जाता है जिसमें heads की probability 60% (success की probability) है। 0 से 10 के range के लिए, 10 flips में total heads की संख्या का simulation नीचे दिया गया है:
dist <- rbinom(100, 10, 0.6)
plot(dist)
Bernoulli distribution का PMF और CDF इस प्रकार हैं:
range <- c(0,1,2,3,4,5,6,7,8,9,10)
pmf <- dbinom(x=range, size = 10,prob = 0.6)
cdf <- pbinom(q = range, size = 10, prob = 0.6)
plot_pmf(pmf,range)
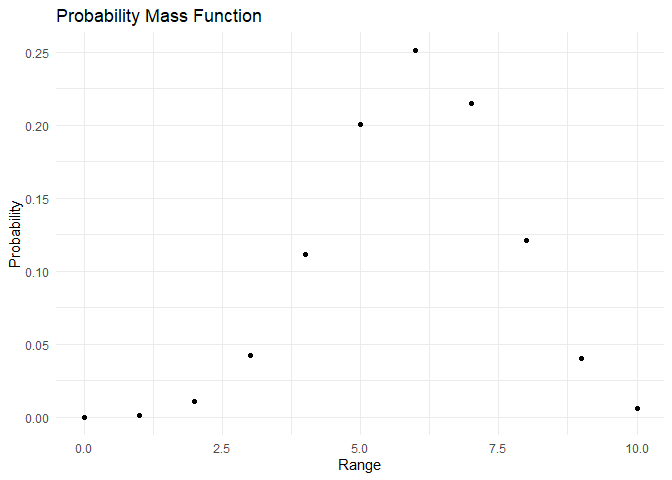
plot_cdf(cdf, range)
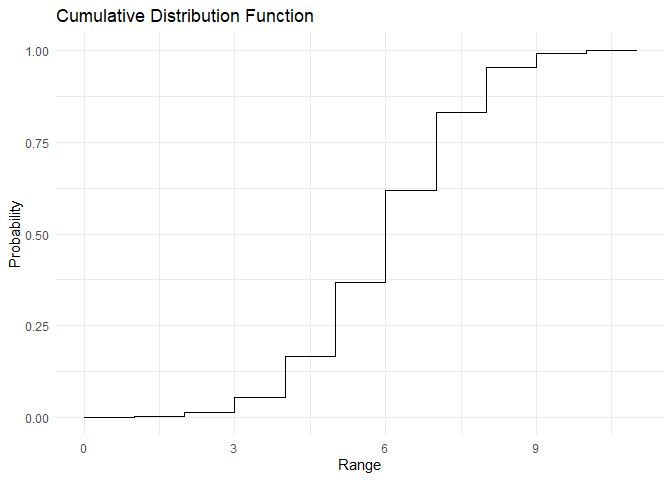
Binomial distribution का mean और variance \(E[X] = np\) और \(Var[X] = npq\) हैं। इसे नीचे दिखाए गए तरीके से निकाला जा सकता है और नीचे दिए गए code का उपयोग करके सत्यापित किया जा सकता है:
Derivations:
\(E[X] = E[Z_1 + Z_2 + ...] = E[Z_1] + E[Z_2] +E[Z_3] + ...E[Z_n] = np\)
जहाँ \(Z_1, Z_2..Z_n\) Bernoulli events हैं जो binomial distribution का निर्माण करते हैं।
\(Var[x] = Var[Z_1 + Z_2 + ...] = Var[Z_1] + Var[Z_2] +Var[Z_3] + ...Var[Z_n] = npq\) क्योंकि \(Z_1, Z_2..Z_n\) स्वतंत्र हैं।
इसे sample data के mean और variance लेकर भी सत्यापित किया जा सकता है:
mean(dist)
## [1] 6.11
var(dist)
## [1] 2.523131
Geometric distribution¶
कल्पना कीजिए एक experiment जिसमें हम स्वतंत्र Bernoulli trials को n बार दोहरा रहे हैं। हम इस distribution को केवल दो parameters, success probability p और trials की संख्या n का उपयोग करके characterize कर सकते हैं। मान लीजिए कि हमें पहले success को n failures के बाद मिलता है। इस event से संबंधित distribution geometric distribution है। Binomial distribution का PMF इस प्रकार दिया जाता है:
\(P(X=x)=p\times (1-p)^{r}\)
इस function की range सभी Real Values हैं 0,1,2,3,4,...
कल्पना कीजिए कि हम coin को flip करते हैं जब तक हमें heads नहीं मिलता, जहाँ heads की probability 50% (success की probability) है। 0 से 10 के range के लिए, पहले heads तक n failures की probability इस प्रकार है:
dist <- rgeom(100, 0.5)
plot(dist)
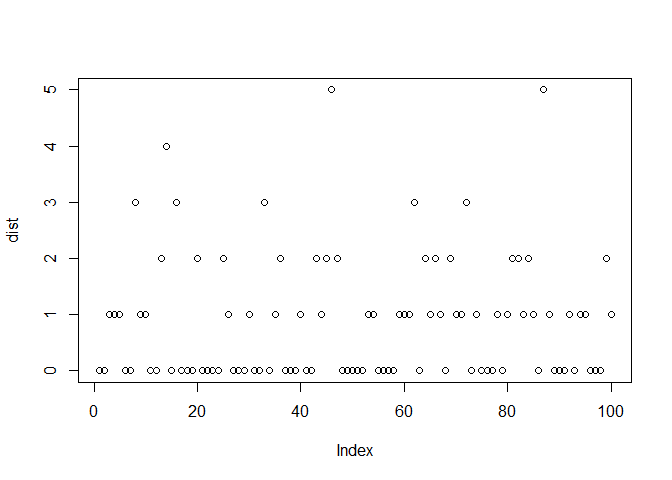
Geometric distribution का PMF और CDF इस प्रकार हैं:
range <- c(0,1,2,3,4,5,6,7,8,9,10)
pmf <- dgeom(x=range, prob = 0.5)
cdf <- pgeom(q = range,prob = 0.5)
plot_pmf(pmf,range)
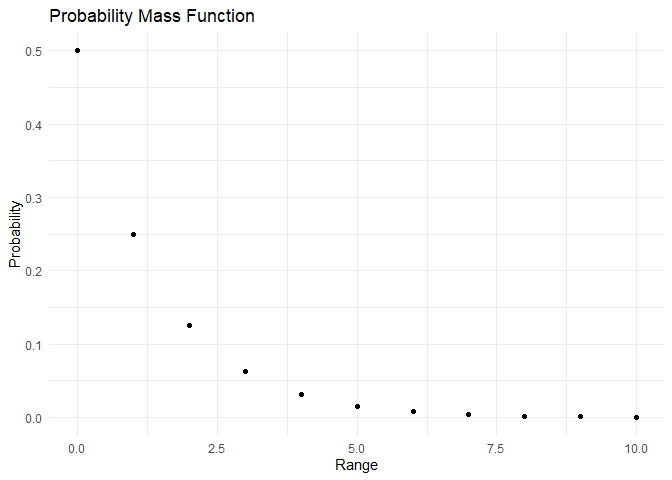
plot_cdf(cdf, range)
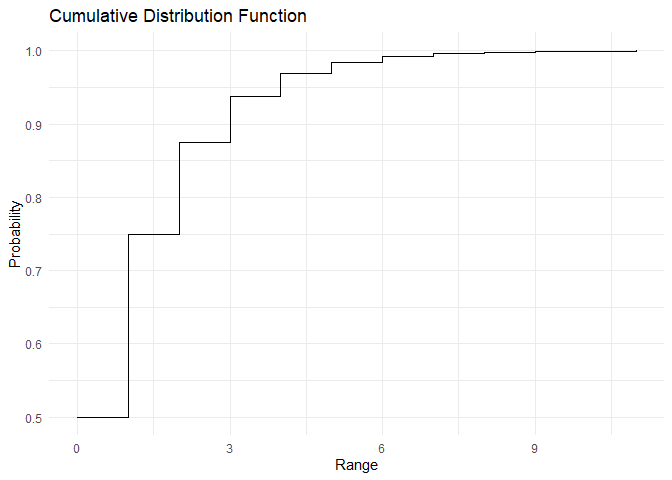
Geometric distribution का mean और variance \(E[X] = \frac{q}{p}\) और \(Var[X] = \frac{q}{p^2}\) हैं। इसे नीचे दिखाए गए तरीके से निकाला जा सकता है और नीचे दिए गए code का उपयोग करके सत्यापित किया जा सकता है:
Derivations:
\(E[X] = 0p+1qp+2q^2p+3q^3p+..=qp(1+2q+3q^2+..) = qp\frac{1}{(1-q)^2} = q/p\)
\(Var[x] = E[X^2]-E[X]^2 = (0p+1qp+4q^2p+9q^3p+..) -(\frac{q}{p})^2 = \frac{q}{p^2}\)
इसे sample data के mean और variance लेकर भी सत्यापित किया जा सकता है:
mean(dist)
## [1] 0.86
var(dist)
## [1] 1.232727
Poisson distribution¶
Poisson distribution का उपयोग तब किया जाता है जब हम एक समय के interval में successes की संख्या को गिनते हैं। आमतौर पर, इन स्थितियों में, किसी विशेष समय पर event होने की probability कम होती है। उदाहरण के लिए, हम एक bus stand में एक समय के दौरान आने वाले customers की संख्या को गिनने में रुचि रखते हैं। यह random variable एक Poisson distribution का पालन कर सकता है क्योंकि success की probability; किसी भी समय bus stand पर आने वाले व्यक्ति की probability कम होती है। Poisson distribution को परिभाषित करने के लिए केवल एक parameter का उपयोग किया जाता है, अर्थात् \(\lambda\), जो arrivals की औसत दर है जिसमें हम रुचि रखते हैं। PMF इस प्रकार परिभाषित किया गया है:
$$ P(X=x)= \frac{\lambdaxe $$ इस function की range सभी Real Values हैं 0,1,2,3,4,... }}{x!
\(\lambda =10\) के लिए Poisson distribution के लिए हम:
dist <- rpois(100, 10)
plot(dist)
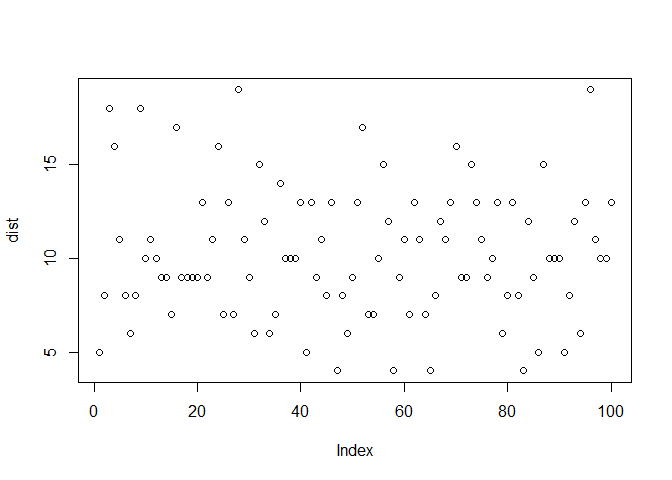
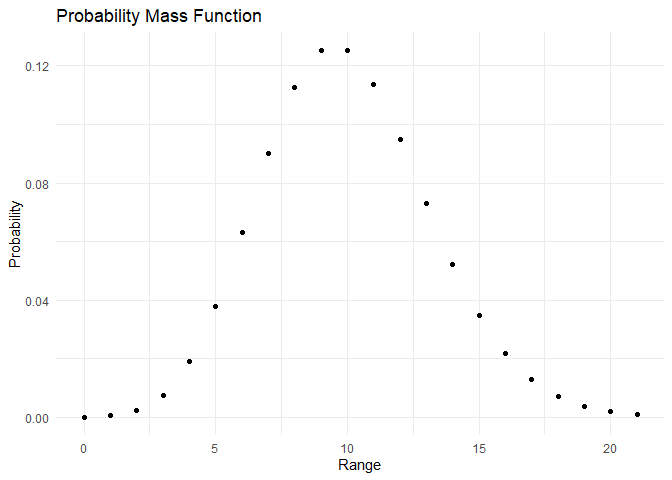
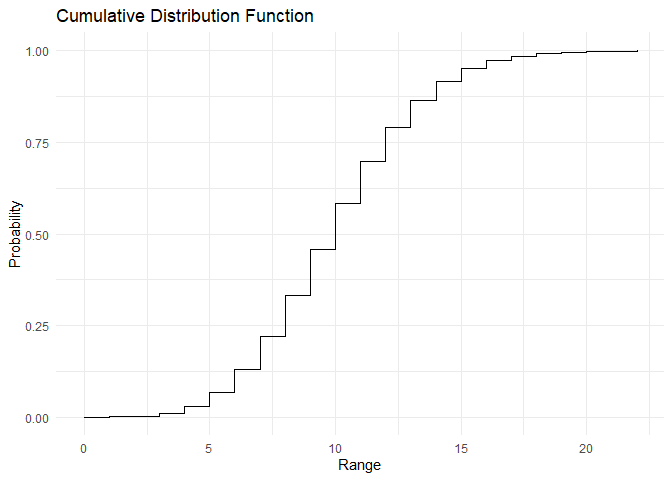
Poisson distribution का PMF और CDF इस प्रकार हैं:
range <- c(0,1,2,3,4,5,6,7,8,9,10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21)
pmf <- dpois(x=range, lambda = 10)
cdf <- ppois(q = range, lambda = 10)
plot_pmf(pmf,range)
plot_cdf(cdf, range)
Poisson distribution का mean और variance \(E[X] = \lambda\) और \(Var[X] = \lambda\) हैं। इसे नीचे दिखाए गए तरीके से निकाला जा सकता है और नीचे दिए गए code का उपयोग करके सत्यापित किया जा सकता है:
Derivations:
\(E[X] = \sum x\frac{\lambda^xe^{-\lambda}}{x!} = \lambda \sum\frac{\lambda^{x-1}e^{-1}}{(x-1)!} = \lambda\)
इसे sample data के mean और variance लेकर भी सत्यापित किया जा सकता है:
mean(dist)
## [1] 10.24
var(dist)
## [1] 12.28525
Continuous random variables¶
Discrete random variables के विपरीत, continuous random variables किसी interval में सभी real values ले सकते हैं जो finite या infinite हो सकती हैं। एक continuous random variable X का probability density function \(f_X(X)\) होता है। PDF और PMF में अंतर होता है जबकि event की probability की गणना में उनका उपयोग समान होता है। उदाहरण के लिए, event A की probability को प्रत्येक discrete variable (PMF) की probabilities को जोड़कर गणना की जाती है, जबकि continuous variables (PDF) के लिए सभी outcomes की probabilities को integrate करके गणना की जाती है। इसी तरह, CDF के लिए, हम \(-\infty\) से x तक integrate करते हैं।
\(PDF:= f_X(x)\)
\(P(X\in A) = \int_A f_X(y) dy\)
\(CDF:= F_X(x) = \int_{-\infty}^{x} f_x(y) dy\)
इसलिए PDF और CDF को \(\frac{d}{dx}F(X) = f(x)\) और \(P(X \in (x+\epsilon, x-\epsilon)) = 2\epsilon \times f(x)\) के द्वारा जोड़ा जाता है।
Uniform distribution¶
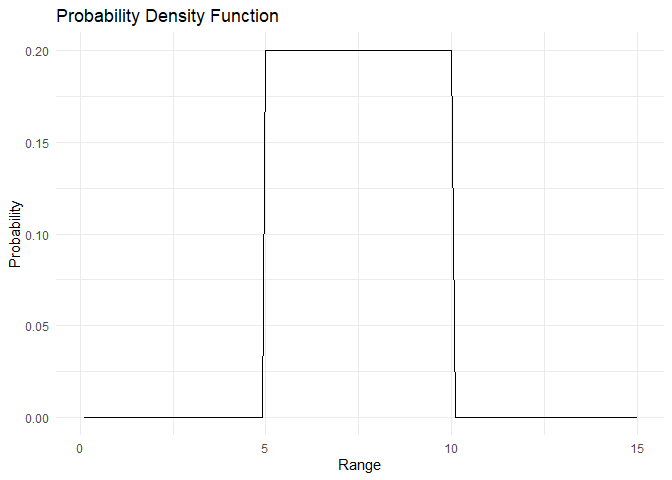
Uniform distribution का उपयोग तब किया जाता है जब हमारे पास underlying distribution नहीं होता। हम एक simplifying assumption बनाते हैं कि हमारे range में हर element के होने की probability समान होती है। Uniform distribution का PDF इस प्रकार दिया जाता है:
\(PDF:= f(x) = \frac{1}{b-a}, \, x \in (a,b)\)
हमें uniform distribution को characterize करने के लिए दो parameters की आवश्यकता होती है, जो a और b होते हैं। Distribution इस प्रकार है:
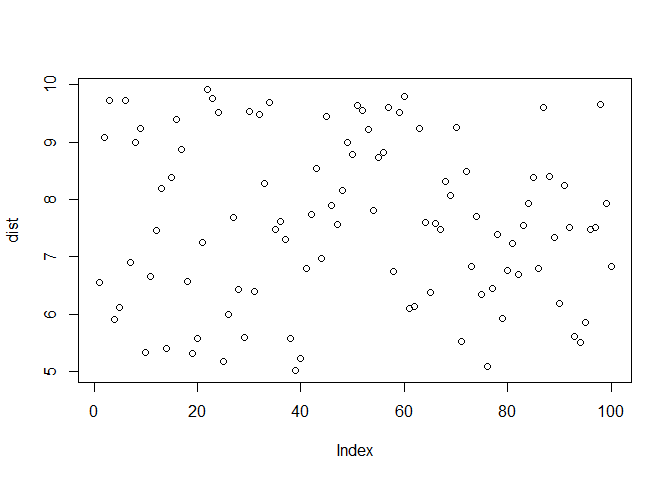
dist <- runif(n = 100, min = 5, max = 10)
plot(dist)
PDF और CDF नीचे plot किए गए हैं:
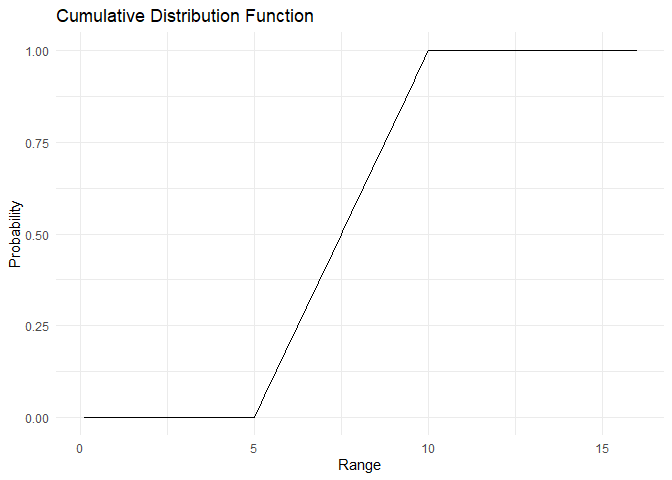
range <- 1:150/10
pdf <- dunif(x=range, min=5, max=10)
cdf <- punif(q = range, min=5, max=10)
plot_pdf(pdf,range)
plot_cdf_continuous(cdf, range)
Uniform distribution के लिए, mean \(E[X]=\frac{a+b}{2}\) और variance \(Var[X] = \frac{(a-b)^2}{12}\) है। इसे साबित किया जा सकता है:
\(E[X] = \int_a^bx\times\frac{1}{b-a}dx = \frac{a+b}{2}\)
\(Var[X] = E[X^2] - E[X]^2 = \int_a^b x^2\times \frac{1}{b-a}dx - (\frac{a+b}{2})^2 = \frac{(b^3-a^3)}{3(b-a)}- \frac{(a+b)^2}{4} = \frac{a^2+b^2+ab}{4}-\frac{(a+b)^2}{4} = \frac{(a-b)^2}{12}\)
इसे sample data के mean और variance लेकर भी सत्यापित किया जा सकता है:
mean(dist)
## [1] 7.592581
var(dist)
## [1] 2.017721
Exponential distribution¶
Geometric distribution में, हमने पहले success के होने की probability को n failures के बाद देखा। Exponential distribution में, हम यह देखते हैं कि किसी event के होने तक कितना समय लगता है, या events के बीच elapsed time। Exponential distribution को वर्णित करने के लिए केवल एक parameter \(\lambda\) की आवश्यकता होती है, जो unit time में successes का वर्णन करता है। Exponential distribution का PDF इस प्रकार दिया जाता है:
\(PDF:= f(x) = \lambda\times e^{-\lambda x}\)
CDF को इस प्रकार निकाला जा सकता है:
\(CDF = P(X<x) = F(X) = \int_0^x \lambda\times e^{-\lambda y} dy = 1-e^{-\lambda x}\)
इसलिए 1-CDF को इस प्रकार लिखा जा सकता है:
\(P(X>x) = e^{-\lambda x}\)
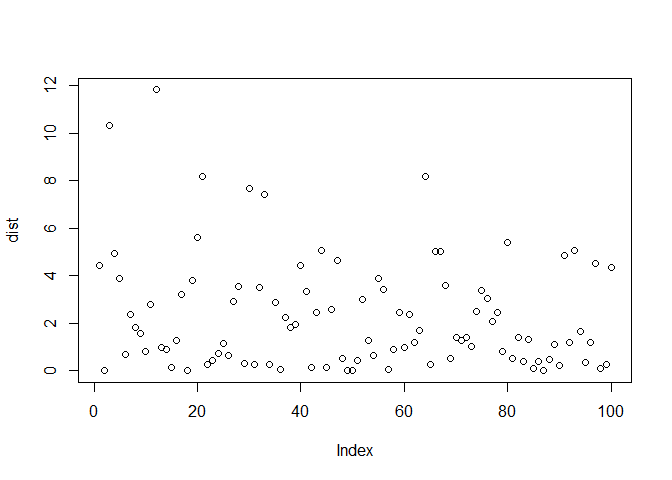
interval \(x>0\) और \(\lambda>0\)। यदि एक event औसतन हर दो मिनट में होता है, तो distribution इस प्रकार है:
dist <- rexp(n = 100,rate = 0.5)
plot(dist)
PDF और CDF नीचे plot किए गए हैं:
range <- 1:150/10
pdf <- dexp(x=range, rate= 0.5)
cdf <- pexp(q = range, rate = 0.5)
plot_pdf(pdf,range)
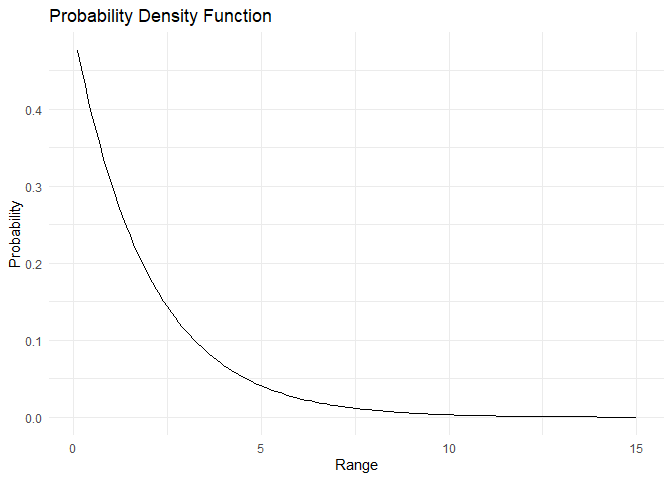
plot_cdf_continuous(cdf, range)
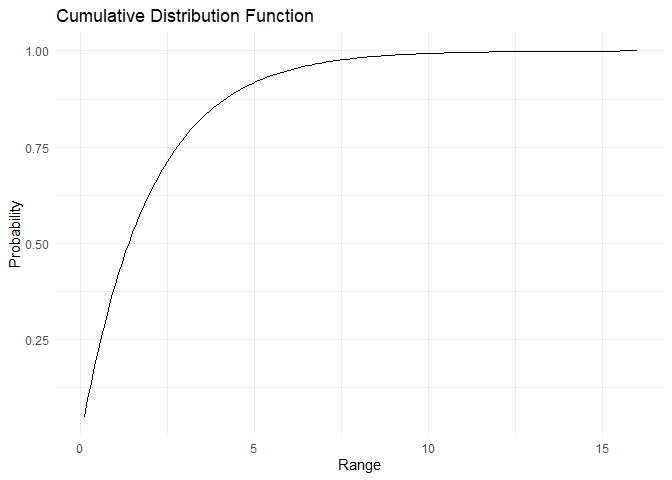
Exponential distribution के लिए, mean \(E[X]=\frac{1}{\lambda}\) और variance \(Var[X] = \frac{1}{\lambda^2}\) है।
इसे sample data के mean और variance लेकर भी सत्यापित किया जा सकता है:
mean(dist)
## [1] 2.309103
var(dist)
## [1] 5.504272
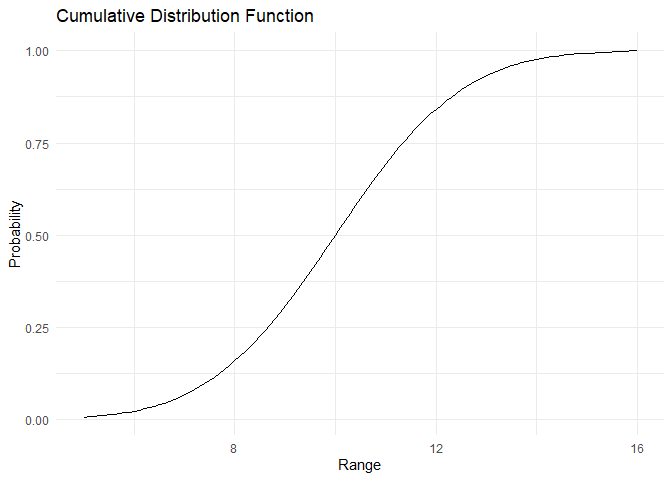
Normal distribution¶
Normal distribution सबसे प्रसिद्ध continuous distribution है। इसका एक अद्वितीय bell-shaped curve होता है। Randomness सामान्यतः एक normal distribution के रूप में प्रस्तुत होती है। यह प्रकृति में व्यापक है। Normal distribution को परिभाषित करने के लिए दो parameters होते हैं, इसका mean \(\mu\) और standard deviation \(\sigma\)।
\(PDF:= f(x) = \frac{1}{2\pi \sigma^2}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\)
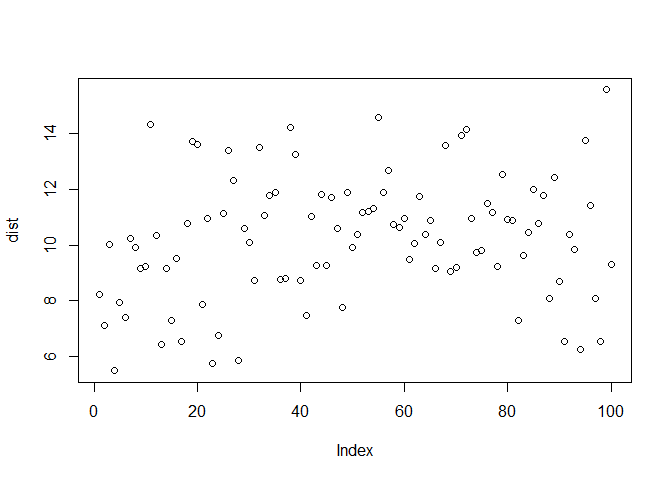
Mean 10 और standard deviation 2 के साथ distribution इस प्रकार है:
dist <- rnorm(n = 100,mean = 10, sd = 2)
plot(dist)
PDF और CDF नीचे plot किए गए हैं:
range <- 50:150/10
pdf <- dnorm(x=range, mean = 10, sd = 2)
cdf <- pnorm(q = range, mean = 10, sd = 2)
plot_pdf(pdf,range)
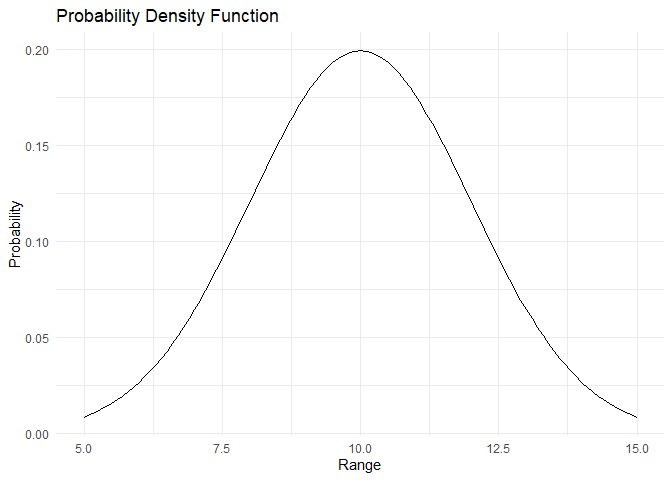
plot_cdf_continuous(cdf, range)
References¶
- Blitzstein, JK और Hwang, J (2014). Introduction to Probability. CRC Press LLC
- Dinesh Kumar (2019). Business Analytics: the science of Data-Driven Decision Making