DBSCAN का उपयोग करके भारत में ट्रेन की देरी का विश्लेषण¶
उपयोग का अवलोकन¶
भारत के विशाल रेलवे नेटवर्क में ट्रेन की देरी एक सामान्य चुनौती है, जो प्रतिदिन लाखों यात्रियों को प्रभावित करती है। इन देरी के पीछे के पैटर्न को समझना शेड्यूलिंग को अनुकूलित करने और संचालन की दक्षता में सुधार करने में मदद कर सकता है। इस ब्लॉग में, हमने वास्तविक समय की ट्रेन चलने की स्थिति डेटा एकत्र किया, देरी के मेट्रिक्स की गणना की, और स्टेशनों के बीच देरी के भौगोलिक और समय संबंधी पैटर्न की पहचान के लिए क्लस्टरिंग तकनीकों को लागू किया। लक्ष्य यह है कि उन हॉटस्पॉट्स को उजागर किया जाए जहां देरी अक्सर होती है और उनकी गंभीरता का विश्लेषण किया जाए।
from bs4 import BeautifulSoup
import requests
import pandas as pd
import numpy as np
BeautifulSoup के साथ वेब स्क्रैपिंग¶
ट्रेन की देरी का डेटा एकत्र करने के लिए, हमने BeautifulSoup का उपयोग किया, जो HTML और XML दस्तावेजों को पार्स करने के लिए एक Python लाइब्रेरी है। डेटा runningstatus.in से प्राप्त किया गया, जो लाइव ट्रेन स्थिति अपडेट प्रदान करता है। BeautifulSoup ने हमें यह करने की अनुमति दी:
1. स्टेशन के नाम, निर्धारित और वास्तविक आगमन/प्रस्थान समय, और देरी की जानकारी वाले HTML तालिकाओं से संरचित डेटा निकालना।
2. HTML टैग में असंगतताओं को संभालना और स्टेशन कोड के लिए <abbr> और देरी की स्थिति के लिए <small> जैसे नेस्टेड तत्वों को पार्स करना।
3. निकाले गए डेटा को आगे के विश्लेषण के लिए pandas DataFrame में बदलना।
इस दृष्टिकोण ने हजारों ट्रेनों के लिए डेटा संग्रह को स्वचालित किया, जिससे 26,000 से अधिक पंक्तियों का एक समृद्ध डेटासेट बना।
ट्रेन Janmabhoomi express के लिए, हमारे पास लाइव चलने की स्थिति में निम्नलिखित है:
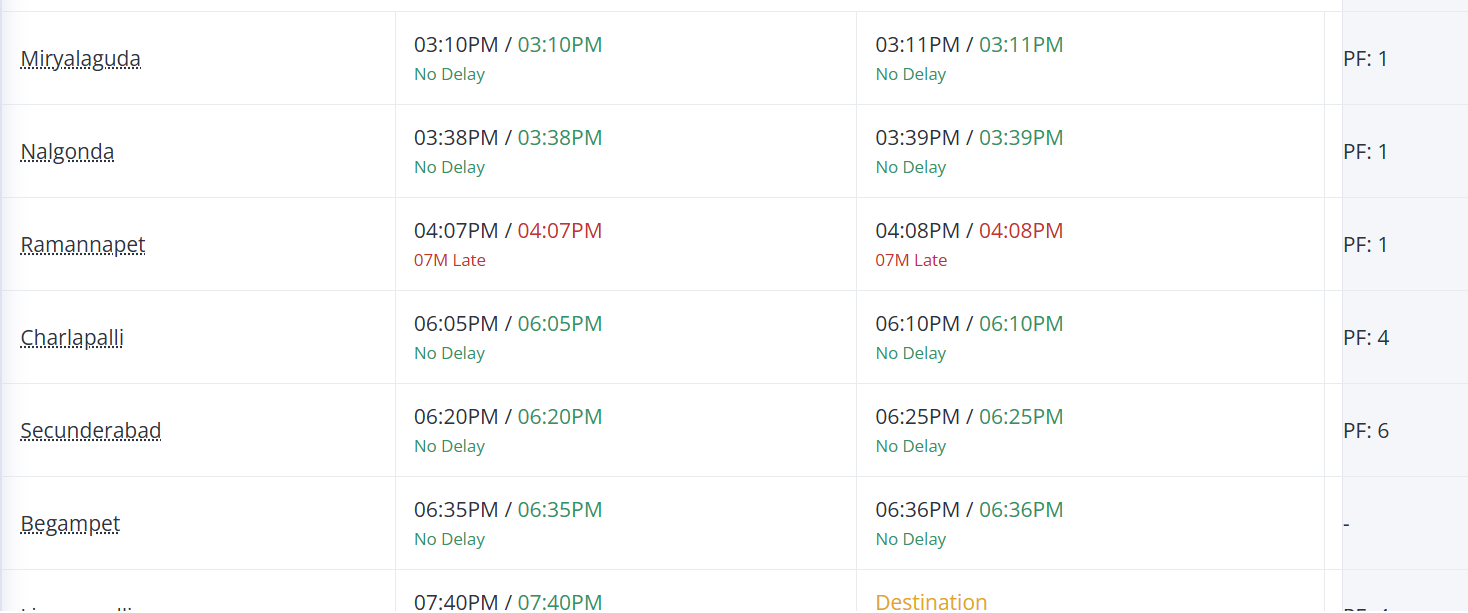
संबंधित HTML कोड है:
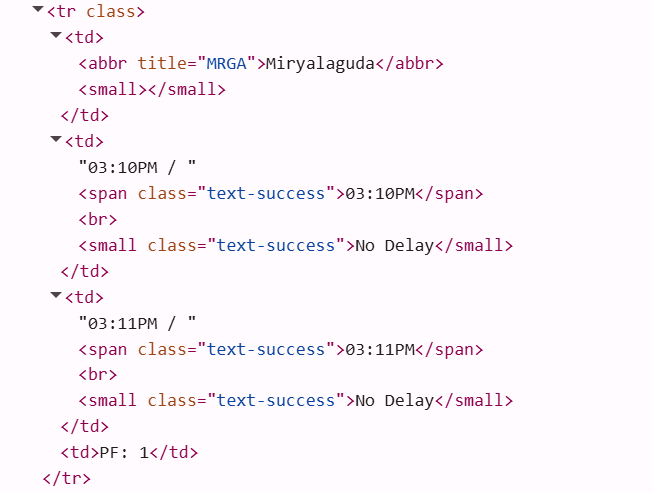
def get_table(train_number):
# लिंक दो इनपुट लेता है, ट्रेन नंबर और तारीख YYYYMMDD (2025-12-13) में
link = 'https://runningstatus.in/status/'+ str(train_number)+'-on-20251213'
try:
response = requests.get(link, timeout=15)
except:
# टाइमआउट तब होता है जब तारीख पर ट्रेन नंबर के लिए कोई ट्रेन नहीं होती
print("timeout for", train_number)
return pd.DataFrame()
if response.status_code == 200:
page_content = response.text
soup = BeautifulSoup(page_content, 'html.parser')
else:
print(train_number, 'Failed')
return pd.DataFrame()
table = soup.find("table")
last_updated = None
for thead in table.find_all("thead"):
# thead में तालिका में हेडर पंक्ति होती है
last_row = thead.find("tr")
# tr पंक्ति है
if last_row:
td = last_row.find("td", colspan=True)
if td and "Last Updated" in td.get_text(strip=True):
last_updated = td.get_text(strip=True)
break
rows = []
tbody = table.find("tbody")
for tr in tbody.find_all("tr"):
# td प्रत्येक सेल (तालिका डेटा) है
tds = tr.find_all("td")
if len(tds) != 4:
continue
# 4 पंक्तियाँ होनी चाहिए
# --- स्टेशन सेल ---
station_cell = tds[0]
abbr = station_cell.find("abbr") # यह स्टेशन नाम का संक्षिप्त रूप है
station_name = abbr.get_text(strip=True) if abbr else station_cell.get_text(strip=True)
station_code = abbr["title"] if (abbr and abbr.has_attr("title")) else None
delay_small = station_cell.find("small") # यह देरी की स्थिति है
delay_status = delay_small.get_text(strip=True) if delay_small else None
# --- आगमन सेल ---
arrival_cell = tds[1]
arrival_text = arrival_cell.get_text(" ", strip=True) # उदाहरण: "02:11 PM / 02:11 PM" या "Source"
arrival_status_tag = arrival_cell.find("span")
arrival_status = arrival_status_tag.get_text(strip=True) if arrival_status_tag else None
# यदि आगमन समय मौजूद है तो उसे पार्स करें
arr_sch, arr_act = None, None
if "/" in arrival_text:
parts = [p.strip() for p in arrival_text.split("/")]
if len(parts) == 2:
arr_sch, arr_act = parts
# --- प्रस्थान सेल ---
departure_cell = tds[2]
departure_text = departure_cell.get_text(" ", strip=True) # उदाहरण: "02:12 PM / 02:12 PM" या "Destination"
departure_status_tag = departure_cell.find("span")
departure_status = departure_status_tag.get_text(strip=True) if departure_status_tag else None
dep_sch, dep_act = None, None
if "/" in departure_text:
parts = [p.strip() for p in departure_text.split("/")]
if len(parts) == 2:
dep_sch, dep_act = parts
# --- PF सेल ---
pf = tds[3].get_text(strip=True)
rows.append({
"Station Name": station_name,
"Station Code": station_code,
"Delay Status": delay_status,
"Arrival Scheduled": arr_sch,
"Arrival Actual": arr_act,
"Arrival Status": arrival_status,
"Departure Scheduled": dep_sch,
"Departure Actual": dep_act,
"Departure Status": departure_status, # उदाहरण: "Destination"
"PF": pf
})
df = pd.DataFrame(rows)
df['train_number'] = train_number
print(train_number)
return df
Superfast express Trains आमतौर पर 12XXX या 22XXX के रूप में होती हैं। यह विश्लेषण सुपरफास्ट ट्रेनों पर केंद्रित है, क्योंकि ये नियमित रूप से चलती हैं और प्रमुख स्टेशनों को कवर करती हैं।
train_details = pd.DataFrame()
for train_number in range(12101, 12999):
train_details = pd.concat([train_details, get_table(train_number)], ignore_index=False)
for train_number in range(22101, 22999):
train_details = pd.concat([train_details, get_table(train_number)], ignore_index=False)
train_details
| Station Name | Station Code | Delay Status | Arrival Scheduled | Arrival Actual | Arrival Status | Departure Scheduled | Departure Actual | Departure Status | PF | train_number | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Lokmanyatilak | LTT | None | None | Source | 08:35PM | 08:36PM 01M Late | 08:36PM | PF: 3 | 12101 | |
| 1 | Kalyan | KYN | 58 Km/Hr | 09:12PM | 09:35PM 23M Late | 09:35PM | 09:15PM | 09:45PM 30M Late | 09:45PM | PF: 4 | 12101 |
| 2 | Bhusaval | BSL | 30 Km/Hr | 02:50AM | 03:20AM 30M Late | 03:20AM | 02:55AM | 03:28AM 33M Late | 03:28AM | PF: 5 | 12101 |
| 3 | Akola | AK | 120 Km/Hr | 04:50AM | 05:20AM 30M Late | 05:20AM | 04:55AM | 05:24AM 29M Late | 05:24AM | PF: 2 | 12101 |
| 4 | Badnera | BD | 105 Km/Hr | 06:20AM | 06:36AM 16M Late | 06:36AM | 06:23AM | 06:39AM 16M Late | 06:39AM | PF: 2 | 12101 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 27 | Keshorai Patan | KPTN | 126 Km/Hr | 09:23AM | 09:37AM 14M Late | 09:37AM | 09:25AM | 09:43AM 18M Late | 09:43AM | PF: 1 | 22998 |
| 28 | Kota | KOTA | 95 Km/Hr | 09:50AM | 09:57AM 07M Late | 09:57AM | 10:00AM | 10:08AM 08M Late | 10:08AM | PF: 2 | 22998 |
| 29 | New Kota | NKOT | 64 Km/Hr | 10:13AM | 10:21AM 08M Late | 10:21AM | 10:15AM | 10:24AM 09M Late | 10:24AM | PF: 2 | 22998 |
| 30 | Ramganj Mandi | RMA | 121 Km/Hr | 11:03AM | 11:14AM 11M Late | 11:14AM | 11:05AM | 11:19AM 14M Late | 11:19AM | PF: 1 | 22998 |
| 31 | Jhalawar City | JLWC | 55 Km/Hr | 12:05PM | 12:02PM No Delay | 12:02PM | None | None | Destination | PF: 1 | 22998 |
26152 rows × 11 columns
train_details.columns = ['station_name', 'station_code', 'delay_status', 'scheduled_arrival', 'actual_arrival', 'arrival_status', 'scheduled_departure', 'actual_departure', 'departure_status', 'pf', 'train_number']
प्रस्थान और आगमन समय में देरी जैसे वेरिएबल बनाना।
train_details[['actual_departure', 'delay_departure']] = train_details['actual_departure'].str.split('M', n=1, expand=True)
train_details[['actual_arrival', 'arrival_departure']] = train_details['actual_arrival'].str.split('M', n=1, expand=True)
time_cols = ['scheduled_arrival', 'actual_arrival', 'scheduled_departure', 'actual_departure']
train_details['actual_departure'] = train_details['actual_departure'] + 'M'
train_details['actual_arrival'] = train_details['actual_arrival'] + 'M'
for time_col in time_cols:
train_details[time_col] = pd.to_datetime(train_details[time_col])
देरी के वेरिएबल बनाना
train_details['arrival_delay'] = (train_details.actual_arrival - train_details.scheduled_arrival)/pd.Timedelta(minutes=1)
train_details['departure_delay'] = (train_details.actual_departure - train_details.scheduled_departure)/pd.Timedelta(minutes=1)
train_details['arrival_delay'] = np.maximum(0, train_details['arrival_delay'].fillna(0))
train_details['departure_delay'] = np.maximum(0, train_details['departure_delay'].fillna(0))
train_details
# मध्यरात्रि की समस्याओं के लिए फ़िल्टरिंग:
# जब दिन बदलता है और आगमन मध्यरात्रि के तुरंत बाद होता है, तो देरी को 24*60=1440 के रूप में दिखाया जाता है बजाय वास्तविक देरी के
train_details.loc[train_details.arrival_delay >= 1350, 'arrival_delay'] = 1440 - train_details[train_details.arrival_delay >= 1350].arrival_delay
train_details.sort_values('arrival_delay', ascending=True).tail(25)
| Unnamed: 0 | station_name | station_code | delay_status | scheduled_arrival | actual_arrival | arrival_status | scheduled_departure | actual_departure | departure_status | pf | train_number | delay_departure | arrival_departure | arrival_delay | departure_delay | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3491 | 32 | Howrah | HWH | 98 Km/Hr | 2025-12-14 07:35:00 | 2025-12-14 15:28:00 | 03:28PM | NaT | NaT | Destination | PF: 10 | 12334 | NaN | 7H 53M Late | 473.0 | 0.0 |
| 13082 | 15 | Rourkela | ROU | -4 Km/Hr | 2025-12-14 12:57:00 | 2025-12-14 20:57:00 | 08:57PM | 2025-12-14 13:05:00 | 2025-12-14 21:41:00 | 09:41PM | PF: 3 | 12871 | 8H 36M Late | 8H Late | 480.0 | 516.0 |
| 3490 | 31 | Bardhaman | BWN | 4 Km/Hr | 2025-12-14 05:46:00 | 2025-12-14 13:53:00 | 01:53PM | 2025-12-14 05:50:00 | 2025-12-14 13:56:00 | 01:56PM | PF: 3 | 12334 | 8H 6M Late | 8H 7M Late | 487.0 | 486.0 |
| 4571 | 33 | Mathura | MTJ | 91 Km/Hr | 2025-12-14 02:55:00 | 2025-12-14 11:05:00 | 11:05AM | 2025-12-14 02:57:00 | 2025-12-14 11:08:00 | 11:08AM | PF: 2 | 12409 | 8H 11M Late | 8H 10M Late | 490.0 | 491.0 |
| 23263 | 18 | Joychandi Pahar | JOC | 21 Km/Hr | 2025-12-14 06:50:00 | 2025-12-14 15:10:00 | 03:10PM | 2025-12-14 06:52:00 | 2025-12-14 15:36:00 | 03:36PM | - | 22844 | 8H 44M Late | 8H 20M Late | 500.0 | 524.0 |
| 975 | 5 | Bina | BINA | 13 Km/Hr | 2025-12-14 00:50:00 | 2025-12-14 09:11:00 | 09:11AM | 2025-12-14 00:53:00 | 2025-12-14 09:15:00 | 09:15AM | PF: 3 | 12162 | 8H 22M Late | 8H 21M Late | 501.0 | 502.0 |
| 842 | 5 | Adra | ADRA | 101 Km/Hr | 2025-12-14 00:05:00 | 2025-12-14 09:10:00 | 09:10AM | 2025-12-14 00:10:00 | 2025-12-14 09:17:00 | 09:17AM | PF: 1 | 12152 | 9H 7M Late | 9H 5M Late | 545.0 | 547.0 |
| 977 | 7 | Itarsi | ET | 96 Km/Hr | 2025-12-14 04:15:00 | 2025-12-14 13:20:00 | 01:20PM | 2025-12-14 04:20:00 | 2025-12-14 13:23:00 | 01:23PM | PF: 2 | 12162 | 9H 3M Late | 9H 5M Late | 545.0 | 543.0 |
| 976 | 6 | Rani Kamalapati | RKMP | 91 Km/Hr | 2025-12-14 02:40:00 | 2025-12-14 11:46:00 | 11:46AM | 2025-12-14 02:50:00 | 2025-12-14 11:56:00 | 11:56AM | PF: 5 | 12162 | 9H 6M Late | 9H 6M Late | 546.0 | 546.0 |
| 978 | 8 | Timarni | TBN | 130 Km/Hr | 2025-12-14 04:58:00 | 2025-12-14 14:09:00 | 02:09PM | 2025-12-14 05:00:00 | 2025-12-14 14:10:00 | 02:10PM | PF: 1 | 12162 | 9H 10M Late | 9H 11M Late | 551.0 | 550.0 |
| 4572 | 34 | Hazrat Nizamuddin | NZM | 68 Km/Hr | 2025-12-14 05:00:00 | 2025-12-14 14:11:00 | 02:11PM | NaT | NaT | Destination | PF: 2 | 12409 | NaN | 9H 11M Late | 551.0 | 0.0 |
| 23264 | 19 | Purulia | PRR | 55 Km/Hr | 2025-12-14 07:30:00 | 2025-12-14 16:41:00 | 04:41PM | 2025-12-14 07:32:00 | 2025-12-14 16:45:00 | 04:45PM | PF: 3 | 22844 | 9H 13M Late | 9H 11M Late | 551.0 | 553.0 |
| 979 | 9 | Harda | HD | 83 Km/Hr | 2025-12-14 05:11:00 | 2025-12-14 14:26:00 | 02:26PM | 2025-12-14 05:13:00 | 2025-12-14 14:28:00 | 02:28PM | PF: 3 | 12162 | 9H 15M Late | 9H 15M Late | 555.0 | 555.0 |
| 13083 | 16 | Raj Gangpur | GP | 40 Km/Hr | 2025-12-14 13:30:00 | 2025-12-14 22:48:00 | 10:48PM | 2025-12-14 13:32:00 | 2025-12-14 22:51:00 | 10:51PM | PF: 1 | 12871 | 9H 19M Late | 9H 18M Late | 558.0 | 559.0 |
| 843 | 6 | Purulia | PRR | 55 Km/Hr | 2025-12-14 00:55:00 | 2025-12-14 10:22:00 | 10:22AM | 2025-12-14 01:00:00 | 2025-12-14 10:25:00 | 10:25AM | PF: 3 | 12152 | 9H 25M Late | 9H 27M Late | 567.0 | 565.0 |
| 13084 | 17 | Garpos | GPH | 53 Km/Hr | 2025-12-14 13:56:00 | 2025-12-14 23:24:00 | 11:24PM | 2025-12-14 13:57:00 | 2025-12-14 23:25:00 | 11:25PM | PF: 1 | 12871 | 9H 28M Late | 9H 28M Late | 568.0 | 568.0 |
| 980 | 10 | Khandwa Junction | KNW | 91 Km/Hr | 2025-12-14 06:43:00 | 2025-12-14 16:20:00 | 04:20PM | 2025-12-14 06:45:00 | 2025-12-14 16:25:00 | 04:25PM | PF: 5 | 12162 | 9H 40M Late | 9H 37M Late | 577.0 | 580.0 |
| 981 | 11 | Burhanpur | BAU | 130 Km/Hr | 2025-12-14 07:38:00 | 2025-12-14 17:16:00 | 05:16PM | 2025-12-14 07:40:00 | 2025-12-14 17:18:00 | 05:18PM | PF: 1 | 12162 | 9H 38M Late | 9H 38M Late | 578.0 | 578.0 |
| 13085 | 18 | Bamra | BMB | 109 Km/Hr | 2025-12-14 14:01:00 | 2025-12-14 23:39:00 | 11:39PM | 2025-12-14 14:02:00 | 2025-12-14 23:41:00 | 11:41PM | PF: 1 | 12871 | 9H 39M Late | 9H 38M Late | 578.0 | 579.0 |
| 982 | 12 | Bhusaval | BSL | 115 Km/Hr | 2025-12-14 08:25:00 | 2025-12-14 18:03:00 | 06:03PM | 2025-12-14 08:30:00 | 2025-12-14 08:30:00 | 08:30AM | PF: 4 | 12162 | 9H 38M Late | 9H 38M Late | 578.0 | 0.0 |
| 13086 | 19 | Bagdihi | BEH | 128 Km/Hr | 2025-12-14 14:13:00 | 2025-12-14 23:53:00 | 11:53PM | 2025-12-14 14:14:00 | 2025-12-14 23:53:00 | 11:53PM | PF: 2 | 12871 | 9H 39M Late | 9H 40M Late | 580.0 | 579.0 |
| 844 | 7 | Chakaradharpur | CKP | 85 Km/Hr | 2025-12-14 02:55:00 | 2025-12-14 12:37:00 | 12:37PM | 2025-12-14 02:57:00 | 2025-12-14 12:41:00 | 12:41PM | PF: 1 | 12152 | 9H 44M Late | 9H 42M Late | 582.0 | 584.0 |
| 23265 | 20 | Tatanagar | TATA | 53 Km/Hr | 2025-12-14 09:30:00 | 2025-12-14 19:21:00 | 07:21PM | 2025-12-14 09:55:00 | 2025-12-14 09:55:00 | 09:55AM | PF: 2 | 22844 | 9H 51M Late | 9H 51M Late | 591.0 | 0.0 |
| 845 | 8 | Rourkela | ROU | 78 Km/Hr | 2025-12-14 04:20:00 | 2025-12-14 14:42:00 | 02:42PM | 2025-12-14 04:28:00 | 2025-12-14 14:49:00 | 02:49PM | PF: 3 | 12152 | 10H 21M Late | 10H 22M Late | 622.0 | 621.0 |
| 846 | 9 | Jharsuguda | JSG | 71 Km/Hr | 2025-12-14 06:13:00 | 2025-12-14 17:03:00 | 05:03PM | 2025-12-14 06:15:00 | 2025-12-14 17:08:00 | 05:08PM | PF: 1 | 12152 | 10H 53M Late | 10H 50M Late | 650.0 | 653.0 |
स्टेशन स्तर पर देरी का डेटासेट बनाना। छोटे स्टेशनों (जो दिन में 10 से कम ट्रेन स्टॉप करते हैं) को नजरअंदाज करना।
delays = train_details.groupby(['station_name', 'station_code']).aggregate({
'arrival_delay': 'mean',
'departure_delay': 'mean',
'delay_status': 'count'
}).reset_index()
delays = delays[delays.delay_status>=10].reset_index(drop=True)
delays.sort_values('delay_status', ascending=False)
| station_name | station_code | arrival_delay | departure_delay | delay_status | |
|---|---|---|---|---|---|
| 556 | Vijayawada | BZA | 6.866337 | 7.564356 | 187 |
| 514 | Surat | ST | 5.010204 | 5.663265 | 187 |
| 94 | Bhusaval | BSL | 13.020513 | 11.815385 | 185 |
| 229 | Itarsi | ET | 10.010471 | 10.460733 | 183 |
| 550 | Vadodara | BRC | 7.391753 | 6.835052 | 182 |
| ... | ... | ... | ... | ... | ... |
| 215 | Harpalpur | HPP | 17.600000 | 18.100000 | 10 |
| 220 | Hindaun City | HAN | 37.400000 | 37.100000 | 10 |
| 241 | Jamtara | JMT | 59.900000 | 60.000000 | 10 |
| 214 | Harihar | HRR | 2.300000 | 2.300000 | 10 |
| 40 | Aunrihar | ARJ | 36.600000 | 29.200000 | 10 |
577 rows × 5 columns
Google Maps API के साथ जियोकोडिंग¶
भौगोलिक रूप से देरी को दृश्य बनाने के लिए, हमें प्रत्येक स्टेशन के लिए अक्षांश और देशांतर की आवश्यकता थी। Google Geocoding API का उपयोग स्टेशन नामों को कोऑर्डिनेट्स में बदलने के लिए किया गया:
1. "Station Name (Code) Railway station, India" जैसे क्वेरी बनाए गए ताकि सटीकता में सुधार हो सके।
2. परिणामों को भारत से संबंधित सुनिश्चित करने के लिए क्षेत्र पूर्वाग्रह (region='in') लागू किया गया।
3. JSON प्रतिक्रियाओं को पार्स करके lat और lng मान निकाले गए।
इस चरण ने भारत में देरी को मानचित्रित करने की अनुमति दी, जिससे यह स्पष्ट हो गया कि देरी के क्लस्टर कहां होते हैं।
import config
import requests
def get_lat_lng(location, gmaps_key=config.gmaps_key, region_bias = 'in'):
"""
Returns (lat, lng) for a given location using Google Geocoding API.
Raises informative exceptions on common failure modes.
"""
url = "https://maps.googleapis.com/maps/api/geocode/json"
params = {
"address": location,
"key": gmaps_key,
}
# वैकल्पिक: क्षेत्र पूर्वाग्रह (उदाहरण: "in" भारत के लिए) प्रासंगिकता में सुधार के लिए
if region_bias:
params["region"] = region_bias
response = requests.get(url, params=params, timeout=15)
response.raise_for_status() # नेटवर्क/HTTP-स्तरीय त्रुटियाँ
payload = response.json()
status = payload.get("status")
if status != "OK":
# सामान्य स्थिति: ZERO_RESULTS, OVER_QUERY_LIMIT, REQUEST_DENIED, INVALID_REQUEST
error_message = payload.get("error_message")
return 0,0
results = payload.get("results", [])
if not results:
return 0,0
location_obj = results[0]["geometry"]["location"] # जब स्थिति == OK हो तो यह निश्चित है
lat = location_obj["lat"]
lng = location_obj["lng"]
return lat, lng
delays['address'] = delays['station_name']+' ('+ delays.station_code + ') Railway station, India'
delays[['lat','long']] = delays['address'].apply(lambda addr: pd.Series(get_lat_lng(addr), index=["lat", "lng"]))
delays
| station_name | station_code | arrival_delay | departure_delay | delay_status | address | lat | long | |
|---|---|---|---|---|---|---|---|---|
| 0 | Abhaipur | AHA | 5.785714 | 5.857143 | 13 | Abhaipur (AHA) Railway station, India | 25.215607 | 86.322353 |
| 1 | Abu Road | ABR | 2.250000 | 1.975000 | 38 | Abu Road (ABR) Railway station, India | 24.480749 | 72.785071 |
| 2 | Achhnera | AH | 33.800000 | 34.200000 | 17 | Achhnera (AH) Railway station, India | 27.177370 | 77.753791 |
| 3 | Adoni | AD | 16.208333 | 16.541667 | 21 | Adoni (AD) Railway station, India | 15.631882 | 77.275883 |
| 4 | Adra | ADRA | 33.920000 | 28.640000 | 24 | Adra (ADRA) Railway station, India | 23.496133 | 86.676755 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 572 | Washim | WHM | 0.687500 | 0.875000 | 14 | Washim (WHM) Railway station, India | 20.103064 | 77.148166 |
| 573 | Yadgir | YG | 19.050000 | 19.000000 | 17 | Yadgir (YG) Railway station, India | 16.742595 | 77.133291 |
| 574 | Yelahanka | YNK | 5.352941 | 6.470588 | 16 | Yelahanka (YNK) Railway station, India | 13.104980 | 77.591798 |
| 575 | Yerraguntla | YA | 22.437500 | 23.062500 | 15 | Yerraguntla (YA) Railway station, India | 14.645948 | 78.549873 |
| 576 | Yesvantpur | YPR | 1.421053 | 2.605263 | 28 | Yesvantpur (YPR) Railway station, India | 13.023212 | 77.551373 |
577 rows × 8 columns
# मैपिंग समस्याओं को ठीक करना
delays.loc[delays.address == 'Kareli (KY) Railway station, India', ['lat', 'long']] = [22.931886, 79.066079]
DBSCAN के साथ क्लस्टरिंग¶
क्लस्टरिंग के लिए, हमने scikit-learn से DBSCAN (Density-Based Spatial Clustering of Applications with Noise) का उपयोग किया। DBSCAN इस उपयोग के मामले के लिए आदर्श है क्योंकि:
1. यह समान देरी पैटर्न वाले स्टेशनों के क्लस्टर की पहचान करता है बिना पहले से क्लस्टरों की संख्या की आवश्यकता के।
2. यह शोर को प्रभावी ढंग से संभालता है, आउटलेयर (विशेष देरी व्यवहार वाले स्टेशन) को -1 के लेबल के साथ चिह्नित करता है।
3. यह देरी के मेट्रिक्स के साथ मिलकर स्थानिक डेटा के साथ अच्छी तरह से काम करता है।
सुनिश्चित करने के लिए कि क्लस्टरिंग निष्पक्ष है, हमने DBSCAN लागू करने से पहले आगमन की देरी और स्टेशन के कोऑर्डिनेट्स को MinMaxScaler का उपयोग करके सामान्यीकृत किया:
1. eps = 0.07 (सामान्यीकृत इकाइयों में दूरी का थ्रेशोल्ड)
2. min_samples = 5 (क्लस्टर बनाने के लिए न्यूनतम बिंदु)
परिणाम: स्टेशन देरी की गंभीरता और भौगोलिक निकटता के आधार पर क्लस्टरों में समूहित हो गए, जिससे पुरानी देरी के हॉटस्पॉट का पता चला।
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import MinMaxScaler
import numpy as np
scaler = MinMaxScaler().set_output(transform="pandas")
X = scaler.fit_transform(delays[['arrival_delay', 'lat', 'long']])
# 3) DBSCAN को एकल eps में मीटर में चलाएँ
eps_meters = 0.07
min_samples = 5
db = DBSCAN(eps=eps_meters, min_samples=min_samples, metric='euclidean')
delays['labels'] = db.fit_predict(X)
delays['labels'].unique()
array([ 0, 1, -1, 2, 3])
# प्रत्येक क्लस्टर का विवरण
delays.groupby('labels').aggregate({
'arrival_delay':['min', 'max', np.mean, np.std],
'departure_delay':['min', 'max', np.mean, np.std]
})
| arrival_delay | departure_delay | |||||||
|---|---|---|---|---|---|---|---|---|
| min | max | mean | std | min | max | mean | std | |
| labels | ||||||||
| -1 | 0.000000 | 113.750000 | 34.124167 | 23.680011 | 0.071429 | 113.833333 | 33.884537 | 24.351357 |
| 0 | 1.470588 | 8.000000 | 4.306110 | 2.471251 | 1.500000 | 8.368421 | 4.545647 | 2.490323 |
| 1 | 0.000000 | 50.615385 | 13.112440 | 9.528010 | 0.000000 | 50.615385 | 13.106862 | 9.426237 |
| 2 | 26.833333 | 35.368421 | 30.642969 | 2.950345 | 26.367647 | 35.894737 | 29.186663 | 3.379501 |
| 3 | 30.615385 | 44.200000 | 38.826864 | 4.979863 | 31.000000 | 45.500000 | 39.613117 | 5.290575 |
क्लस्टर विश्लेषण¶
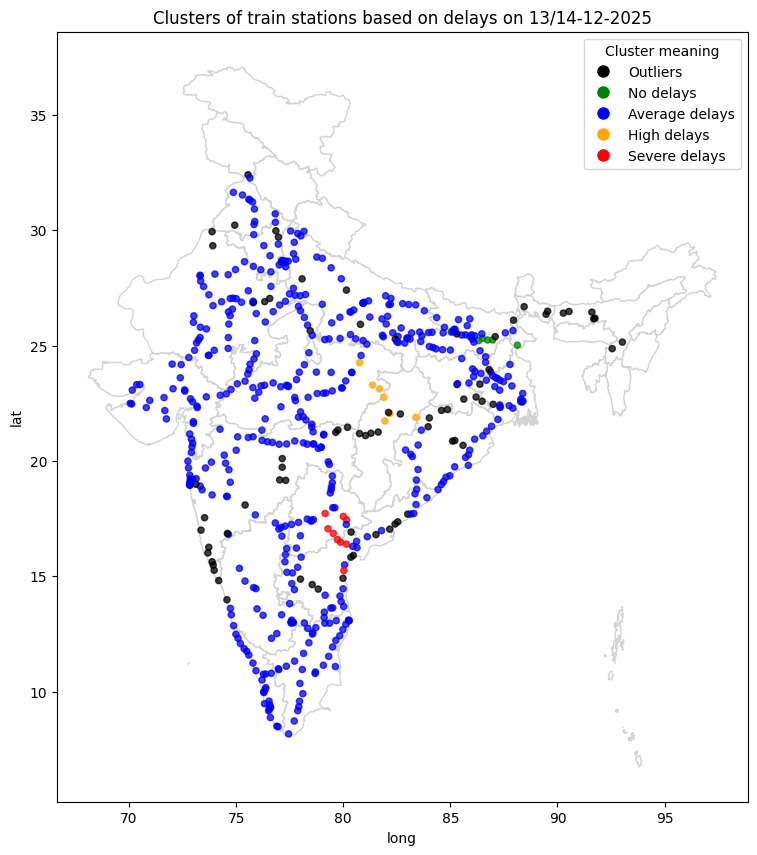
क्लस्टर -1 (शोर, रंग: काला)¶
- आगमन की देरी: औसत ≈ 34.12 मिनट, अधिकतम 113.75 मिनट तक
- प्रस्थान की देरी: औसत ≈ 33.88 मिनट, अधिकतम 113.83 मिनट तक
- व्याख्या: ये अत्यधिक मामले हैं या असामान्य स्टेशन हैं जिनमें बहुत अधिक देरी होती है। DBSCAN इन्हें आउटलेयर के रूप में चिह्नित करता है क्योंकि वे अन्य क्लस्टरों के घनत्व पैटर्न में फिट नहीं होते हैं।
क्लस्टर 0 (न्यूनतम देरी, रंग: हरा, ज्यादातर पटना के पास)¶
- आगमन की देरी: औसत ≈ 4.31 मिनट, अधिकतम ≈ 8 मिनट
- प्रस्थान की देरी: औसत ≈ 4.54 मिनट
- व्याख्या: इस क्लस्टर में स्टेशन अत्यधिक कुशल हैं जिनमें लगभग नगण्य देरी होती है। संभवतः प्रमुख हब या अच्छी तरह से प्रबंधित मार्ग हैं।
क्लस्टर 1 (मध्यम देरी, रंग: नीला, भारत का अधिकांश हिस्सा)¶
- आगमन की देरी: औसत ≈ 13.11 मिनट, अधिकतम ≈ 50.61 मिनट
- प्रस्थान की देरी: औसत ≈ 13.10 मिनट
- व्याख्या: ये स्टेशन मध्यम देरी का अनुभव करते हैं, संभवतः भीड़भाड़ या संचालन संबंधी बाधाओं के कारण।
क्लस्टर 2 (उच्च देरी, रंग: पीला, बिलासपुर-रायगढ़ खिंचाव)¶
- आगमन की देरी: औसत ≈ 30.64 मिनट, अधिकतम ≈ 35.36 मिनट
- प्रस्थान की देरी: औसत ≈ 29.18 मिनट
- व्याख्या: स्टेशन लगातार उच्च देरी का सामना कर रहे हैं। ये नेटवर्क में बाधा या बुनियादी ढांचे की सीमाओं वाले क्षेत्र हो सकते हैं।
क्लस्टर 3 (गंभीर देरी, रंग: लाल, ओंगोल-खम्मम-नालगोंडा खिंचाव)¶
- आगमन की देरी: औसत ≈ 38.82 मिनट, अधिकतम ≈ 44.20 मिनट
- प्रस्थान की देरी: औसत ≈ 39.61 मिनट
- व्याख्या: पुरानी देरी के हॉटस्पॉट। संभवतः भारी ट्रैफिक या प्रणालीगत शेड्यूलिंग समस्याओं वाले प्रमुख जंक्शन हैं।
प्रमुख अंतर्दृष्टियाँ¶
- क्लस्टर 0 सबसे अच्छा प्रदर्शन करने वाले स्टेशनों का प्रतिनिधित्व करता है।
- क्लस्टर 2 और 3 महत्वपूर्ण समस्या क्षेत्रों को उजागर करते हैं जिन्हें तत्काल ध्यान देने की आवश्यकता है।
- शोर (-1) में अत्यधिक विसंगतियाँ शामिल हैं—इनकी अलग से जांच की आवश्यकता हो सकती है।
परिणामों का दृश्यन¶
GeoPandas और Matplotlib का उपयोग करके, हमने निम्नलिखित का प्लॉट किया:
1. भारत के मानचित्र पर रंग-कोडित लेबल के साथ क्लस्टर।
2. हीटमैप-शैली के स्कैटर प्लॉट का उपयोग करके देरी की तीव्रता।
ये दृश्यन यह पहचानना आसान बनाते हैं कि देरी कहां केंद्रित है, जैसे प्रमुख जंक्शन या भीड़भाड़ वाले मार्ग।
# डिफ़ॉल्ट रंग सेट करना
my_colors_list = {-1: 'black', 0: 'green', 1: 'blue', 2: 'orange', 3: 'red'}
delays['label_colors'] = delays.labels.map(my_colors_list)
import geopandas as gpd
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
# भारत का मानचित्र जिसमें राज्य की सीमाएँ हैं
map_gdf = gpd.read_file('https://gist.githubusercontent.com/jbrobst/56c13bbbf9d97d187fea01ca62ea5112/raw/e388c4cae20aa53cb5090210a42ebb9b765c0a36/india_states.geojson')
fig, ax = plt.subplots(figsize=(10, 10))
map_gdf.plot(ax=ax, color='white', edgecolor='lightgrey')
delays.plot(x='long', y='lat', c = 'label_colors', kind='scatter', alpha=0.75, ax=ax)
plt.title("Clusters of train stations based on delays on 13/14-12-2025")
# लिजेंड जोड़ना
legend_spec = [
("black", "Outliers"),
("green", "No delays"),
("blue", "Average delays"),
("orange", "High delays"),
("red", "Severe delays"),
]
# लिजेंड हैंडल्स बनाना
handles = [Line2D([0], [0],marker='o', color='w', label=label, markerfacecolor=color, markersize=10) for color, label in legend_spec]
ax.legend(handles=handles, title="Cluster meaning", loc="upper right", frameon=True)
plt.show();
fig, ax = plt.subplots(figsize=(10, 10))
map_gdf.plot(ax=ax, color='white', edgecolor='lightgrey')
delays.plot(x='long', y='lat', s = 'delay_status', c = 'arrival_delay', colormap='Reds', kind='scatter', ax=ax)
plt.title("Average delays on on 13/14-12-2025")
plt.show()
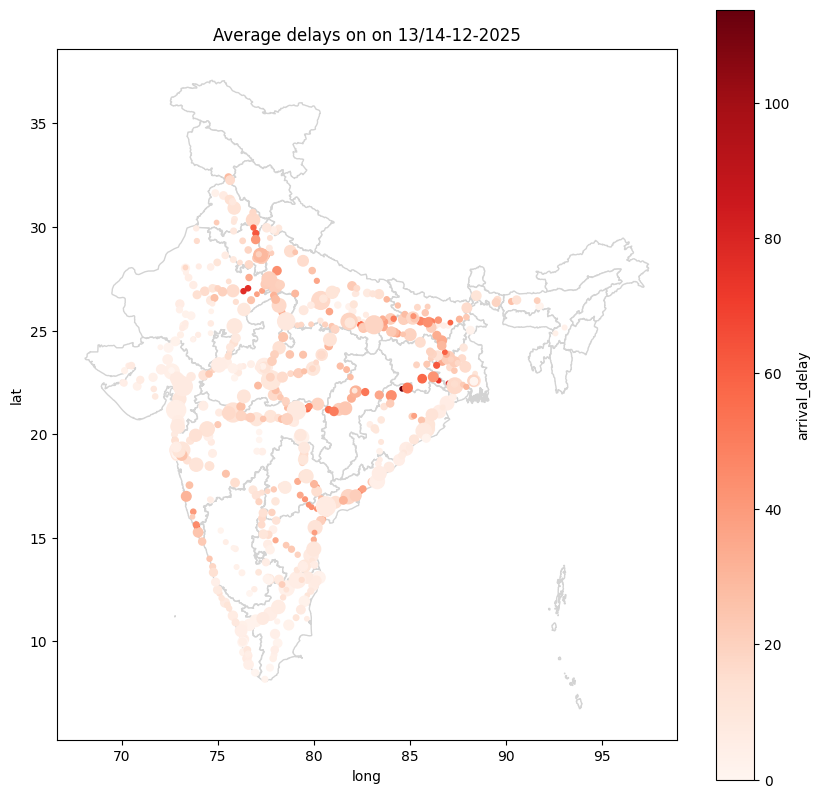
प्रमुख अंतर्दृष्टियाँ¶
- खम्मम और रायगढ़ जैसे स्टेशनों में उच्च देरी की गणना हुई।
- क्लस्टर अक्सर व्यस्त गलियारों के चारों ओर बनते हैं, जो प्रणालीगत भीड़भाड़ को इंगित करते हैं।
- आउटलेयर उन स्टेशनों का प्रतिनिधित्व करते हैं जिनमें असामान्य रूप से उच्च देरी होती है, संभवतः स्थानीय संचालन संबंधी मुद्दों के कारण।
यह ब्लॉग यह प्रदर्शित करता है कि DBSCAN जैसी क्लस्टरिंग तकनीकें भारत के रेलवे नेटवर्क में देरी के हॉटस्पॉट और संचालन की बाधाओं का पता लगाने में कैसे मदद कर सकती हैं। इस दृष्टिकोण को अधिक प्रभावी बनाने के लिए, हम विश्लेषण को लंबे समय तक बढ़ा सकते हैं और मौसम, मौसमी मांग, और रखरखाव के कार्यक्रम जैसे अतिरिक्त कारकों को शामिल कर सकते हैं। ये सुधार पूर्वानुमान मॉडलिंग को सक्षम करेंगे ताकि सक्रिय शेड्यूलिंग और संसाधन आवंटन किया जा सके। संचालन के दृष्टिकोण से, भारतीय रेलवे इन अंतर्दृष्टियों का लाभ उठाकर पुरानी देरी के क्लस्टरों में बुनियादी ढांचे के उन्नयन को प्राथमिकता दे सकता है, गतिशील समय सारणी लागू कर सकता है, और बेहतर विश्वसनीयता और ग्राहक अनुभव के लिए यात्रियों के साथ संचार में सुधार कर सकता है।
(ब्लॉग पाठ को Gen AI द्वारा सुधारा गया)