Data Science के लिए Basic Statistics¶
Statistics एक विज्ञान है जो संख्यात्मक डेटा के संग्रह, विश्लेषण, व्याख्या, और प्रस्तुति से संबंधित है। - Webster's dictionary
किसी भी व्यवसाय में, Retail सहित, statistics का व्यापक रूप से निम्नलिखित कार्यों को करने के लिए उपयोग किया जाता है:
1. विभिन्न KPIs को quantify करना ताकि व्यवसाय का वास्तविक दृश्य प्राप्त हो सके
2. विभिन्न कारकों के बीच कारण-और-प्रभाव संबंधों की पहचान करना
3. व्यवसाय की अंतर्दृष्टि को मान्य करने के लिए hypothesis tests बनाना
4. यह पहचानना कि क्या किसी घटना का व्यवसाय पर महत्वपूर्ण प्रभाव है
Statistics का अध्ययन विभिन्न तरीकों से व्यवस्थित किया जा सकता है। मुख्य तरीकों में से एक statistics को दो शाखाओं में विभाजित करना है: descriptive statistics और inferential statistics। Descriptive और inferential statistics के बीच का अंतर समझने के लिए, population और sample की परिभाषाएँ सहायक होती हैं।
Population¶
यह व्यक्तियों, वस्तुओं, या रुचि के आइटम का संग्रह है। Population एक व्यापक रूप से परिभाषित श्रेणी हो सकती है, जैसे "सभी उत्पाद," या यह संकीर्ण रूप से परिभाषित हो सकती है, जैसे "Store 2105 Bedford Extra में सभी उत्पाद।" एक population लोगों का समूह हो सकता है, जैसे "सभी Tesco के कर्मचारी," या यह वस्तुओं का सेट हो सकता है, जैसे "3 फरवरी, 2007 को बेची गई सभी grocery।"
विश्लेषक population को उस चीज़ के रूप में परिभाषित करता है जिसे वह अध्ययन कर रहा है। उदाहरण के लिए, यदि हम UK में क्रिसमस छुट्टियों का बिक्री पर प्रभाव अध्ययन करना चाहते हैं, तो population UK में क्रिसमस अवधि के दौरान सभी स्टोर्स की बिक्री होगी। यदि अध्ययन पिछले तीन वर्षों के पैटर्न का उपयोग करके अगले वर्ष की बिक्री की भविष्यवाणी करने के लिए है, तो population पिछले तीन वर्षों की बिक्री और अगले वर्ष की बिक्री होगी। सभी विश्लेषण और भविष्यवाणियाँ परिभाषित population तक सीमित होनी चाहिए।
Sample¶
एक sample पूरे का एक भाग है और, यदि सही तरीके से चुना गया हो, तो यह पूरे का प्रतिनिधित्व करता है। विभिन्न कारणों से, विश्लेषक अक्सर पूरी population के बजाय population के sample के साथ काम करना पसंद करते हैं। समय और पैसे की सीमाओं के कारण, एक मानव संसाधन प्रबंधक कंपनी के मनोबल को मापने के लिए 40 कर्मचारियों का एक यादृच्छिक sample ले सकता है, बजाय कि जनगणना का उपयोग करने के।
Inferential vs descriptive analytics¶
यदि एक व्यवसाय विश्लेषक एक समूह पर एकत्रित डेटा का उपयोग उस ही समूह का वर्णन करने या उस पर निष्कर्ष निकालने के लिए कर रहा है, तो statistics को descriptive statistics कहा जाता है। उदाहरण के लिए, यदि एक विश्लेषक एक स्टोर के प्रदर्शन को संक्षिप्त करने के लिए statistics (KPI's) तैयार करता है और उन statistics का उपयोग केवल उस स्टोर के बारे में निष्कर्ष निकालने के लिए करता है, तो statistics descriptive होती हैं।
Statistics की एक और शाखा को inferential statistics कहा जाता है। यदि एक शोधकर्ता एक sample से डेटा एकत्र करता है और उस sample से उत्पन्न statistics का उपयोग population के बारे में निष्कर्ष निकालने के लिए करता है, तो statistics inferential होती हैं। Sample से एकत्रित डेटा का उपयोग किसी बड़े समूह (population) के बारे में कुछ अनुमान लगाने के लिए किया जाता है।
Parameters vs statistics¶
Population का एक descriptive measure को parameter कहा जाता है। Parameters के उदाहरण हैं population mean (\(\mu\)), population variance (\(\sigma^2\)), और population standard deviation (\(\sigma\))।
Sample का एक descriptive measure को statistic कहा जाता है। Statistics के उदाहरण हैं sample mean (\(\bar x\)), sample variance (\(s^2\)), और sample standard deviation (s)।
Data measurement¶
Data के चार प्रकार होते हैं। वे हैं:
1. Nominal: Nominal data का कोई rank नहीं होता। ये डेटा वर्गीकृत और श्रेणीबद्ध करने के लिए उपयोग किए जाते हैं। उदाहरण हैं कर्मचारी पहचान संख्या या उप-समूह की जानकारी। संख्या 5367 वाला कर्मचारी संख्या 5368 वाले कर्मचारी से बड़ा नहीं है।
2. Ordinal: Ordinal data में, डेटा को rank किया जा सकता है, लेकिन दो ranks के बीच का अंतर कोई अर्थ नहीं रखता। इसका उपयोग डेटा को वर्गीकृत करने के लिए भी किया जाता है। उदाहरण के लिए, “Good”, “Average”, “Bad”। Good का rank average से बड़ा है, और average का rank bad से बड़ा है। लेकिन 'good' और 'average' के बीच का अंतर मापने योग्य अर्थ नहीं रखता।
3. Interval: Interval वह डेटा है जिसमें लगातार संख्याओं के बीच की दूरी का अर्थ होता है, और डेटा हमेशा संख्यात्मक होते हैं। Interval data के लिए, zero बस स्केल पर एक और बिंदु है और घटना की अनुपस्थिति नहीं है। Interval data का उदाहरण Fahrenheit तापमान स्केल है।
4. Ratio: Ratio data में interval data की समान विशेषताएँ होती हैं, लेकिन ratio data में एक absolute zero होता है, और दो संख्याओं का ratio अर्थपूर्ण होता है। उदाहरण हैं ऊँचाई, वजन, समय आदि।
Measures of central tendency¶
Measures of central tendency डेटा के मध्य भाग का वर्णन करने के लिए होते हैं। वे हैं:
Mean: Mean एक समूह के संख्याओं का औसत है $ \mu = \frac{\sum x_i}{N} = \frac{x_1+x_2 + ... + x_n}{N} $
Median: Median एक क्रमबद्ध संख्याओं की श्रृंखला में मध्य मान है
Mode: Mode डेटा के सेट में सबसे अधिक बार होने वाला मान है
Percentiles: Percentiles केंद्रीय प्रवृत्ति के माप हैं जो डेटा को 100 भागों में विभाजित करते हैं। 99 percentiles होते हैं क्योंकि डेटा को 100 भागों में विभाजित करने के लिए 99 विभाजक होते हैं। nth percentile वह मान है जिसके नीचे कम से कम n प्रतिशत डेटा होता है और उस मान के ऊपर अधिकतम (100 - n) प्रतिशत होता है। उदाहरण के लिए, 87वां percentile का मतलब है कि कम से कम 87% डेटा उस मान के नीचे है, और उससे अधिकतम 13% डेटा उस मान के ऊपर है।
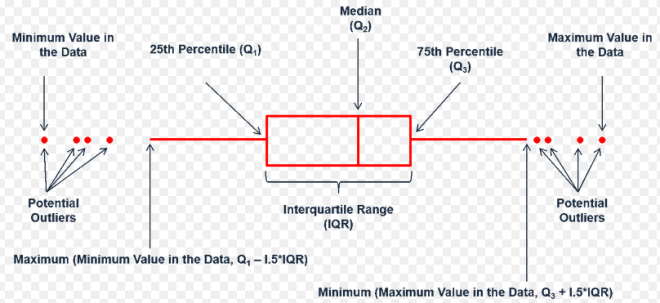
Quartiles: Quartiles स्थिति के माप होते हैं जो डेटा के एक समूह को चार उप-समूहों या भागों में विभाजित करते हैं। तीन quartiles को Q1, Q2, और Q3 के रूप में दर्शाया जाता है। पहला quartile, Q1, डेटा के पहले, या सबसे निचले, एक-चौथाई को ऊपरी तीन-चौथाई से अलग करता है और यह 25वें percentile के बराबर होता है। दूसरा quartile, Q2, डेटा के दूसरे चौथाई को तीसरे चौथाई से अलग करता है। Q2 50वें percentile पर स्थित होता है और डेटा का median होता है। तीसरा quartile, Q3, डेटा के पहले तीन-चौथाई को अंतिम चौथाई से अलग करता है और यह 75वें percentile के मान के बराबर होता है।
Measures of variability¶
Measures of variability डेटा के सेट के फैलाव या वितरण का वर्णन करने के लिए उपयोग किए जाते हैं। वे हैं:
Range: Range डेटा सेट के सबसे बड़े मान और सबसे छोटे मान के बीच का अंतर है।
Interquartile Range: Interquartile range पहले और तीसरे quartile के बीच के मानों की रेंज है। मूलतः, यह डेटा के मध्य 50% का रेंज है और इसे Q3 - Q1 के मान की गणना करके निर्धारित किया जाता है।
Mean Absolute Deviation: Mean absolute deviation (MAD) संख्याओं के सेट के लिए mean के चारों ओर के deviations के absolute मानों का औसत है। $MAD = \frac{\sum |x_i-\mu|}{N} $
Variance: Variance संख्याओं के सेट के लिए arithmetic mean के चारों ओर के वर्गित deviations का औसत है। Population variance को \(\sigma^2\) द्वारा दर्शाया जाता है। \(\sigma^2 = \frac{\sum(x_i-\mu)^2}{N}\)
Standard Deviation: Standard deviation variance का वर्गमूल है। Population standard deviation को \(\sigma\) द्वारा दर्शाया जाता है। \(\sigma = \sqrt(\frac{\sum(x_i-\mu)^2}{N})\)
Measures of shape¶
Measures of shape उपकरण होते हैं जो डेटा के वितरण के आकार का वर्णन करने के लिए उपयोग किए जा सकते हैं। वे हैं:
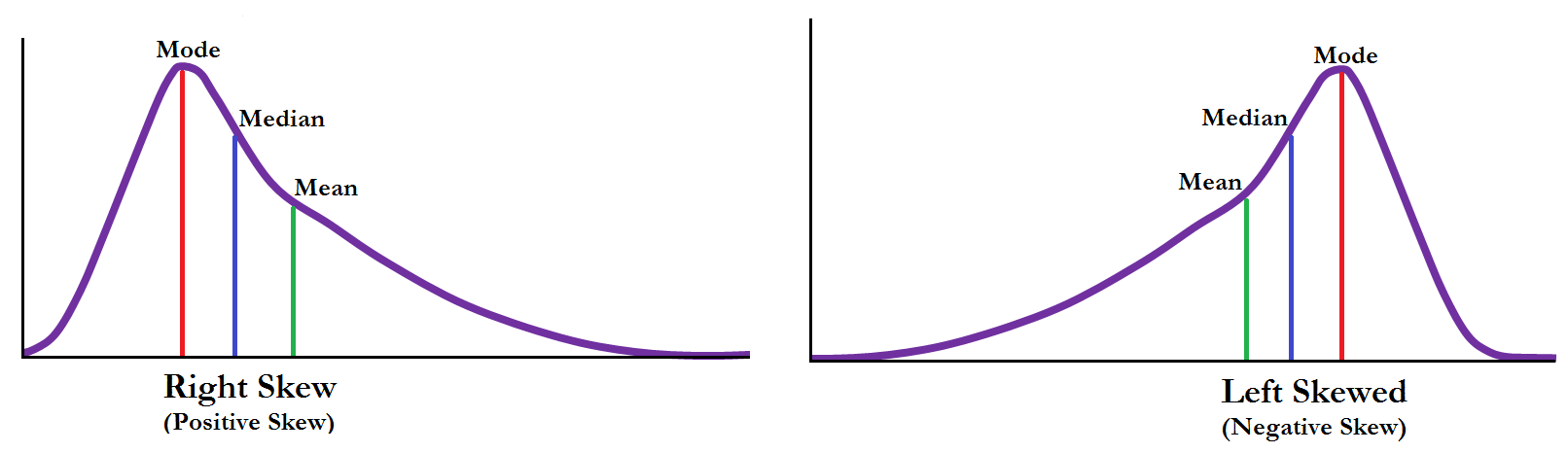
Skewness: Skewness तब होती है जब वितरण असममित होता है या उसमें संतुलन नहीं होता। Skewness का गुणांक \(S_k = \frac{3(\mu-M_d)}{\sigma}\) के रूप में परिभाषित किया जाता है जहां \(M_d\) median है।
 Kurtosis: Kurtosis वितरण में चोटी की मात्रा के रूप में परिभाषित किया जाता है। Kurtosis के तीन प्रकार होते हैं: Leptokurtic, Mesokurtic, Platykurtic distributions.
Kurtosis: Kurtosis वितरण में चोटी की मात्रा के रूप में परिभाषित किया जाता है। Kurtosis के तीन प्रकार होते हैं: Leptokurtic, Mesokurtic, Platykurtic distributions. 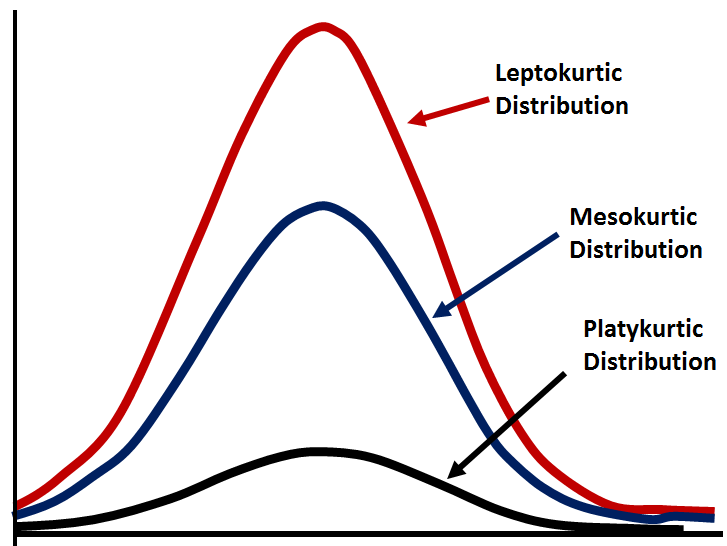
सभी माप सभी डेटा प्रकारों पर उपयोग नहीं किए जा सकते। नीचे दी गई तालिका बताती है कि कौन से माप किस प्रकार के डेटा पर उपयोग किए जा सकते हैं:
| Measure | Nominal | Ordinal | Interval | Ratio |
|---|---|---|---|---|
| Mean | No | No | Yes | Yes |
| Median | No | Yes | Yes | Yes |
| Mode | Yes | Yes | Yes | Yes |
| Percentiles | No | No | Yes | Yes |
| Quartiles | No | No | Yes | Yes |
| Range | No | Yes | Yes | Yes |
| Interquartile Range | No | No | Yes | Yes |
| MAD | No | No | Yes | Yes |
| Variance | No | No | Yes | Yes |
| Std.dev | No | No | Yes | Yes |
| Skewness | No | No | Yes | Yes |
| Kurtosis | No | No | Yes | Yes |
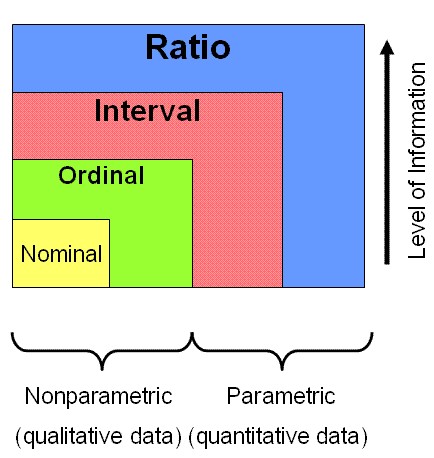 ऊपर दी गई आकृति चार स्तरों के डेटा माप के बीच उपयोग की संभावनाओं के संबंधों को दर्शाती है। समवर्ती वर्ग यह दर्शाते हैं कि डेटा का प्रत्येक उच्च स्तर किसी भी तकनीक का उपयोग करके विश्लेषित किया जा सकता है जो निम्न स्तरों पर उपयोग की जाती है, लेकिन इसके अलावा, इसे अन्य सांख्यिकीय तकनीकों में भी उपयोग किया जा सकता है।
ऊपर दी गई आकृति चार स्तरों के डेटा माप के बीच उपयोग की संभावनाओं के संबंधों को दर्शाती है। समवर्ती वर्ग यह दर्शाते हैं कि डेटा का प्रत्येक उच्च स्तर किसी भी तकनीक का उपयोग करके विश्लेषित किया जा सकता है जो निम्न स्तरों पर उपयोग की जाती है, लेकिन इसके अलावा, इसे अन्य सांख्यिकीय तकनीकों में भी उपयोग किया जा सकता है।
Code and example¶
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
path="../Data/house_prices.csv"
df = pd.read_csv(path)
df.head()
| Price | Living Area | Bathrooms | Bedrooms | Lot Size | Age | Fireplace | |
|---|---|---|---|---|---|---|---|
| 0 | 142212 | 1982 | 1.0 | 3 | 2.00 | 133 | 0 |
| 1 | 134865 | 1676 | 1.5 | 3 | 0.38 | 14 | 1 |
| 2 | 118007 | 1694 | 2.0 | 3 | 0.96 | 15 | 1 |
| 3 | 138297 | 1800 | 1.0 | 2 | 0.48 | 49 | 1 |
| 4 | 129470 | 2088 | 1.0 | 3 | 1.84 | 29 | 1 |
saleprice = df['Price']
mean=saleprice.mean()
median=saleprice.median()
mode=saleprice.mode()
print('Mean: ',mean,'\nMedian: ',median,'\nMode: ',mode[0])
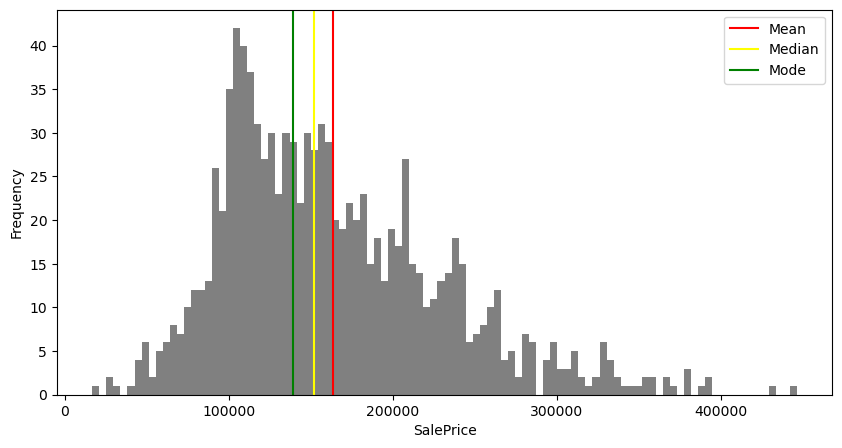
plt.figure(figsize=(10,5))
plt.hist(saleprice,bins=100,color='grey')
plt.axvline(mean,color='red',label='Mean')
plt.axvline(median,color='yellow',label='Median')
plt.axvline(mode[0],color='green',label='Mode')
plt.xlabel('SalePrice')
plt.ylabel('Frequency')
plt.legend()
plt.show()
Mean: 163862.12511938874
Median: 151917.0
Mode: 139079
#minimum value of salePrice
df['Price'].min()
16858
#maximum value of salePrice
df['Price'].max()
446436
#Range
df['Price'].max()-df['Price'].min()
429578
#variance
df['Price'].var()
4576733423.870562
#standard deviation
from math import sqrt
sqrt(df['Price'].var())
67651.55891678005
#50th percentile i.e median(q2)
df['Price'].quantile(0.5)
151917.0
#75th percentile
q3 = df['Price'].quantile(0.75)
q3
205235.0
#25th percentile
q1 = df['Price'].quantile(0.25)
q1
112014.0
#interquartile range
IQR = q3 - q1
IQR
93221.0
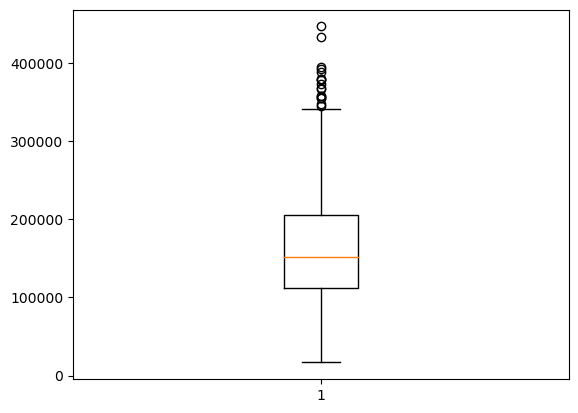
plt.boxplot(df['Price'])
plt.show()
#skewness
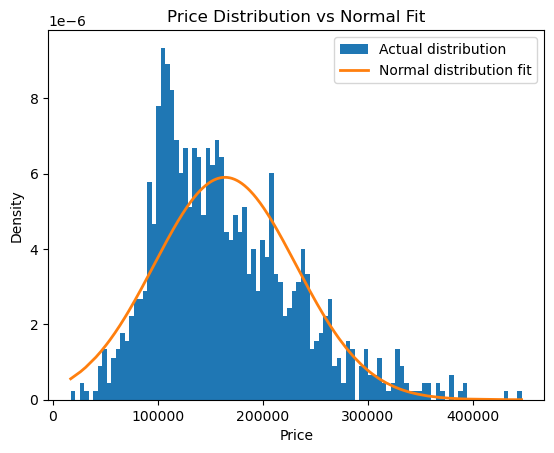
df['Price'].skew()
0.876159910810612
#kurtosis
df['Price'].kurt()
0.7598074495519183
import scipy.stats as stats
# Assuming df is already defined and contains a 'Price' column
prices = np.asarray(df['Price'])
prices_sorted = np.sort(prices)
# Fit a normal distribution with the same mean and standard deviation
fit = stats.norm.pdf(prices_sorted, np.mean(prices_sorted), np.std(prices_sorted))
# Plot the histogram and the fitted normal distribution
plt.hist(prices_sorted, density=True, bins=100, label="Actual distribution")
plt.plot(prices_sorted, fit, '-', linewidth=2, label="Normal distribution fit")
plt.legend()
plt.xlabel("Price")
plt.ylabel("Density")
plt.title("Price Distribution vs Normal Fit")
plt.show();