RAG
RAG: Retrieval-Augmented Generation¶
RAG का मतलब है Retrieval-Augmented Generation। यह एक तकनीक है जो बड़े भाषा मॉडल्स (LLMs) को बढ़ाती है, जिससे उन्हें जनरेशन प्रक्रिया के दौरान बाहरी ज्ञान स्रोतों तक पहुँचने और उन्हें शामिल करने की अनुमति मिलती है। इसका उपयोग चैटबॉट्स में किया जाता है ताकि वे विशेष टेक्स्ट, आंतरिक कंपनी दस्तावेज़, कोड दस्तावेज़, समाचार लेख आदि के आधार पर प्रश्नों के उत्तर दे सकें।
Article reader chatbot¶
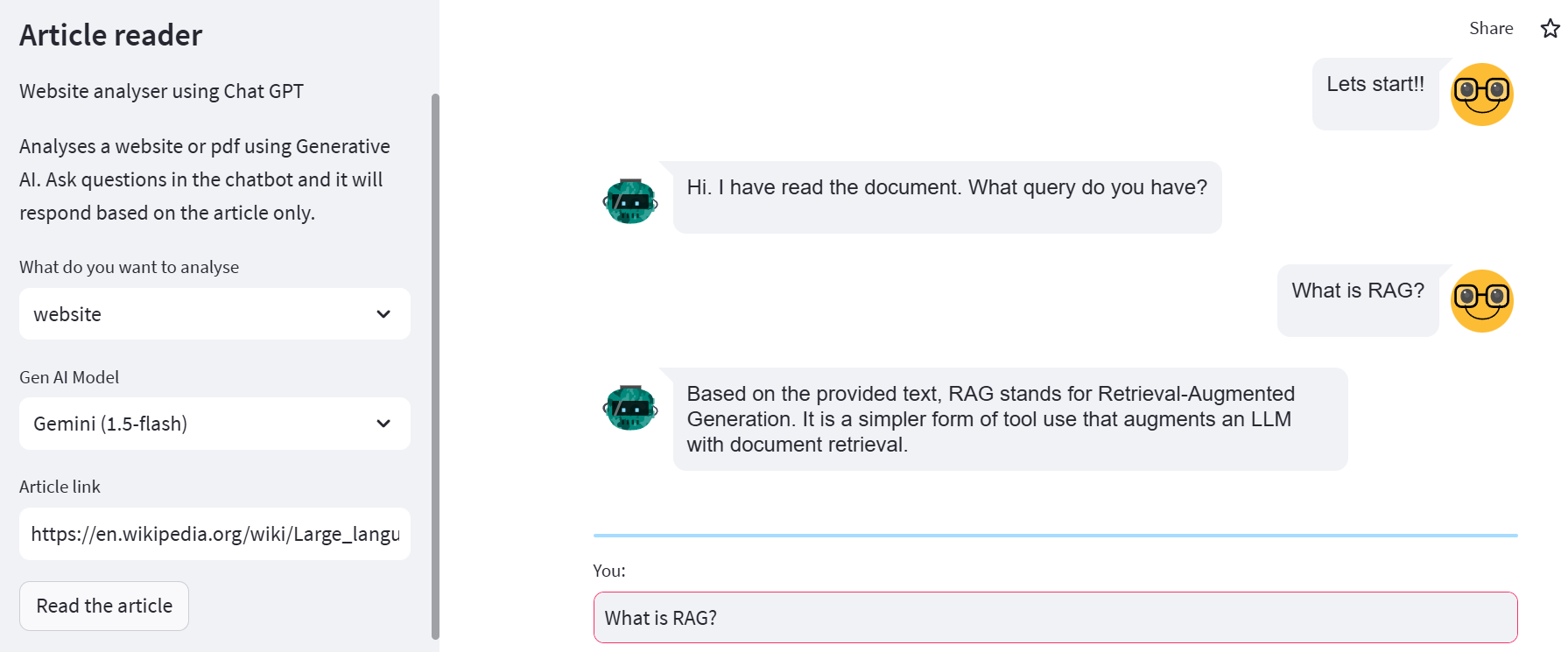
मैंने एक चैटबॉट Article Reader बनाया है जहाँ उपयोगकर्ता एक दस्तावेज़/लिंक अपलोड कर सकते हैं ताकि वे केवल उसी दस्तावेज़ के आधार पर उत्तर प्राप्त कर सकें (वेबसाइट या PDF)। नियमित LLM चैटबॉट्स के विपरीत, यह साझा किए गए दस्तावेज़ों के बाहर के प्रश्नों का उत्तर नहीं देगा। नीचे उपकरण का एक स्क्रीनशॉट दिखाया गया है:
RAG की आवश्यकता क्यों है?¶
- LLMs की सीमाओं को पार करना: LLMs विशाल डेटा सेट्स पर प्रशिक्षित होते हैं, लेकिन उनके पास सबसे अद्यतन या विशिष्ट जानकारी तक पहुँच नहीं हो सकती। RAG इस समस्या का समाधान करता है, LLMs को बाहरी ज्ञान आधारों तक पहुँचने और उनका उपयोग करने का एक तरीका प्रदान करके। हमारे मामले में, हम आंतरिक कंपनी दस्तावेज़ या किसी कंपनी की वार्षिक रिपोर्ट साझा कर सकते हैं और केवल साझा किए गए दस्तावेज़ के आधार पर प्रश्न पूछ सकते हैं।
- सटीकता और प्रासंगिकता में सुधार: बाहरी ज्ञान को शामिल करके, RAG LLMs को अधिक सटीक और प्रासंगिक उत्तर उत्पन्न करने में मदद करता है, विशेष रूप से तथ्यात्मक प्रश्नों या डोमेन-विशिष्ट विषयों से निपटने के समय।
- संदर्भ को बेहतर बनाना: RAG LLMs को बाहरी जानकारी पर विचार करके प्रश्न के संदर्भ को बेहतर ढंग से समझने में सक्षम बनाता है, जिससे अधिक संगत और सूचनात्मक उत्तर मिलते हैं।
- अद्यतन जानकारी: RAG LLMs को बाहरी स्रोतों से नवीनतम जानकारी तक पहुँचने की अनुमति देता है, यह सुनिश्चित करते हुए कि उनके उत्तर वर्तमान और प्रासंगिक हैं।
RAG कैसे काम करता है¶
- Retrieval: LLM एक प्रश्न प्राप्त करता है और बाहरी ज्ञान आधार से प्रासंगिक दस्तावेज़ या अंश प्राप्त करता है।
- Augmentation: प्राप्त जानकारी को LLM के इनपुट में एकीकृत किया जाता है, या तो इसे मूल प्रश्न के साथ जोड़कर या सीधे मॉडल को खिलाकर।
- Generation: LLM बढ़ाए गए इनपुट के आधार पर एक उत्तर उत्पन्न करता है, अपने आउटपुट में बाहरी ज्ञान को शामिल करता है। संक्षेप में, RAG पुनर्प्राप्ति-आधारित मॉडलों (प्रासंगिक जानकारी खोजने के लिए) और जनरेटिव मॉडलों (मानव-जैसे टेक्स्ट उत्पन्न करने के लिए) की ताकतों को जोड़ता है, जिससे एक अधिक शक्तिशाली और बहुपरकारी AI प्रणाली बनती है।
अब हम Open AI का उपयोग करके और एक स्थानीय मॉडल (Llama) का उपयोग करके दो RAG मॉडल अंत-से-अंत बनाएँगे।
RAG using OpenAI¶
मान लीजिए हम किसी व्यक्ति का रिज्यूमे पढ़ना चाहते हैं और उस व्यक्ति के अनुभव के वर्षों का पता लगाना चाहते हैं। हम Article Reader चैटबॉट का उपयोग करके रिज्यूमे अपलोड कर सकते हैं और प्रश्न पूछ सकते हैं।
पहले हम एक रिज्यूमे पढ़ते हैं।
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
import openai
import config
def extract_text_from_pdf(pdf_file):
pdf_text = ''
reader = PdfReader(pdf_file)
for page_no in range(len(reader.pages)):
pdf_text = pdf_text + reader.pages[page_no].extract_text()
if(len(pdf_text)==0):
raise ValueError('No text extracted from this pdf.')
return pdf_text
text_article = extract_text_from_pdf("Harsha_Achyuthuni_resume.pdf")
print("The first 100 chars in the resume are:\n", text_article[:100])
The first 100 chars in the resume are:
Achyuthuni Sri Harsha
Data Scientist, Deloitte, Imperial College London, IIMB, harshaash.com
E-mail:
print("The total number of words in the document are: ", len(text_article.split()))
The total number of words in the document are: 1611
अब हम उस प्रश्न को परिभाषित करते हैं जिसे हम पूछना चाहते हैं:
query = "How many years of experience does the candidate have?"
Retrieval¶
RAG का पहला कदम घनत्व पुनर्प्राप्ति है। यह तकनीक एम्बेडिंग की शक्ति का उपयोग करती है - टेक्स्ट के अद्वितीय संख्यात्मक प्रतिनिधित्व - दस्तावेज़ के भीतर सबसे प्रासंगिक जानकारी को प्रभावी ढंग से खोजने के लिए।
इसे प्राप्त करने के लिए, हम दस्तावेज़ को छोटे, प्रबंधनीय टुकड़ों में तोड़ते हैं। प्रत्येक टुकड़ा फिर एक घनत्व वेक्टर (इसके एम्बेडिंग) में परिवर्तित किया जाता है, जो इसके अर्थ की सार्थकता को पकड़ता है। एम्बेडिंग का यह संग्रह एक इंडेक्स बनाता है, जिससे सिस्टम उपयोगकर्ता के प्रश्न के साथ सबसे निकटता से मेल खाने वाले टुकड़ों को तेजी से खोज सकता है (जो भी एक एम्बेडिंग में परिवर्तित किया जाता है)।
यह एक तीन चरण की प्रक्रिया है:
1. टेक्स्ट प्राप्त करें और वाक्यों को टुकड़ों में विभाजित करें
2. वाक्यों को एम्बेड करें
3. खोज इंडेक्स बनाएं
4. खोजें
Chunking¶
दस्तावेज़ को टुकड़ों में विभाजित करने के कई तरीके हैं जैसे: 1. प्रत्येक वाक्य एक टुकड़ा है
2. प्रत्येक पैराग्राफ एक टुकड़ा है
3. दस्तावेज़ को समान संख्या में टोकन के साथ समान रूप से विभाजित किया जाता है
4. कुछ टुकड़े अर्थ खो देते हैं यदि हम उनके चारों ओर का टेक्स्ट शामिल नहीं करते हैं। इसलिए हम टुकड़े के पहले और बाद में कुछ टेक्स्ट जोड़कर संदर्भ जोड़ सकते हैं।
आइए हम दस्तावेज़ को 100 टोकन के आकार के टुकड़ों में विभाजित करें जिसमें प्रत्येक तरफ 25% ओवरलैप हो।
# Split the text based on tokens into chunks
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name='cl100k_base',
chunk_size=100, # Minimum chunk size is 100
chunk_overlap=25 # Overlap in the chunk size is 25
)
split_texts = text_splitter.split_text(text_article)
split_texts = [Document(page_content = split_texts[i]) for i in range(len(split_texts))]
print("The total number of chunks in the document are: "+str(len(split_texts)))
The total number of chunks in the document are: 34
100 टोकन के आकार के लिए, नीचे दी गई छवि दिखाती है कि टेक्स्ट को कैसे टुकड़ों में विभाजित किया गया है। पीले और लाल रंग में हाइलाइट किए गए अलग-अलग टुकड़े हैं जिनमें सामान्य भाग ओवरलैप है। 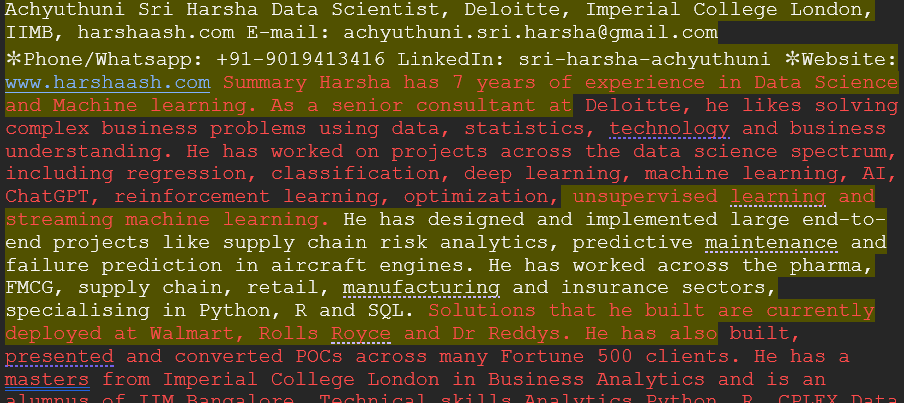
Embedding और खोज इंडेक्स बनाना¶
एम्बेडिंग उत्पन्न करने के लिए, मैं OpenAI के टोकनाइज़र का उपयोग कर रहा हूँ। प्रत्येक टुकड़ा एक एम्बेडिंग वेक्टर में परिवर्तित किया जाता है।
इन एम्बेडिंग को Qdrant का उपयोग करके संग्रहीत किया जाता है, जो एक मुफ्त वेक्टर डेटाबेस है। Qdrant विशेष रूप से बड़ी एम्बेडिंग संग्रहणाओं को संभालने और खोजने के लिए डिज़ाइन किया गया है, जिससे यह मेरे RAG सिस्टम के लिए एक आदर्श विकल्प बनता है। यह मुझे पुनर्प्राप्ति चरण के दौरान सबसे प्रासंगिक जानकारी प्राप्त करने में भी मदद करता है।
# Create embeddings
embeddings = OpenAIEmbeddings(api_key = config.open_api_key, model="text-embedding-3-large")
इन एम्बेडिंग को my_chat_documents नामक एक वेक्टर डेटाबेस में संग्रहीत किया जा रहा है।
# Initialise vector database
qdrant_client = QdrantClient(
url=config.qdrant_url,
api_key=config.qdrant_api_key,
)
# Delete existing collection
qdrant_client.delete_collection(collection_name="my_chat_documents")
# Store embeddings in vector db
qdrant = QdrantVectorStore.from_documents(
split_texts,
embeddings,
url=config.qdrant_url,
api_key=config.qdrant_api_key,
prefer_grpc=True,
collection_name="my_chat_documents",
)
[qdrant_client.get_collections().collections[i].name for i in range(len(qdrant_client.get_collections().collections))]
['my_chat_documents']
Search¶
मैं वेक्टर डेटाबेस का उपयोग करके उस वेक्टर को खोजने जा रहा हूँ जो प्रश्न के निकटतम है। यह समानता स्कोर जैसे cosine similarity का उपयोग करके किया जा सकता है और प्रश्न के लिए एम्बेडिंग वेक्टर बनाकर किया जा सकता है।
# retrieve selected part of the website
qdrant = QdrantVectorStore.from_existing_collection(
embedding=embeddings,
collection_name="my_chat_documents",
url=config.qdrant_url, api_key=config.qdrant_api_key
)
# Find closest chunks
relevant_document_chunks = qdrant.similarity_search(query=query,k=3)
context_list = [d.page_content for d in relevant_document_chunks]
Augmented¶
शीर्ष तीन टुकड़े हैं:
print("\n-----------------------\n".join(context_list))
Summary
Harsha has 7 years of experience in Data Science and Machine learning. As a senior consultant at
Deloitte, he likes solving complex business problems using data, statistics, technology and business
understanding. He has worked on projects across the data science spectrum, including regression,
classification, deep learning, machine learning, AI, ChatGPT, reinforcement learning, optimization,
unsupervised learning and streaming machine learning.
-----------------------
Achyuthuni Sri Harsha
Data Scientist, Deloitte, Imperial College London, IIMB, harshaash.com
E-mail: achyuthuni.sri.harsha@gmail.com ✼Phone/Whatsapp: +91-9019413416
LinkedIn: sri-harsha-achyuthuni ✼Website: www.harshaash.com
Summary
Harsha has 7 years of experience in Data Science and Machine learning. As a senior consultant at
-----------------------
Solutions that he built are currently deployed at Walmart, Rolls Royce and Dr Reddys. He has also
built, presented and converted POCs across many Fortune 500 clients.
He has a masters from Imperial College London in Business Analytics and is an alumnus of IIM
Bangalore.
Technical skills
Analytics Python, R, CPLEX
Data Engineering SQL, Alteryx
Visualisation Tableau, HTML, Javascript
पहले दो टुकड़े (तीन में से) में अनुभव के वर्षों का उल्लेख किया गया है और वे प्रासंगिक हैं। इन तीन टुकड़ों को जोड़ने से मुझे एक व्यापक और बढ़ाया हुआ टेक्स्ट मिलता है जिसका उपयोग उत्पन्न करने के लिए किया जा सकता है।
agumented_search_context = ". ".join(context_list)
Generation¶
प्रॉम्प्ट में, हम एक अतिरिक्त वेरिएबल नामित संदर्भ प्रदान करेंगे जहाँ हम LLM को संदर्भ प्रदान करते हैं। यह संदर्भ उन टुकड़ों का है जो उत्तर के लिए प्रासंगिक हैं।
qna_system_message = '''You will be provided with a text, and your task is to answer the question based on the text alone.
If you are unable to answer or doubtful, please say "I dont know"'''
qna_user_message_template = """
###Context
Here are some documents that are relevant to the question mentioned below.
{context}
###Question
{question}
"""
prompt = [
{'role':'system', 'content': qna_system_message},
{'role': 'user', 'content': qna_user_message_template.format(
context=agumented_search_context,
question=query
)
}
]
openai.api_key = config.open_api_key
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=prompt,
temperature=0
)
prediction = response.choices[0].message.content.strip()
print(prediction)
The candidate has 7 years of experience.
RAG आर्किटेक्चर सही उत्तर खोजने में सक्षम था।
RAG with local models¶
कई संगठन डेटा गोपनीयता और सुरक्षा को प्राथमिकता देते हैं, अक्सर संवेदनशील जानकारी को बाहरी सेवाओं के साथ साझा करने से मना करते हैं। यह पारंपरिक RAG कार्यान्वयन के लिए एक महत्वपूर्ण चुनौती प्रस्तुत करता है, जो अक्सर क्लाउड-आधारित मॉडलों और बाहरी ज्ञान स्रोतों पर निर्भर करते हैं।
इन चिंताओं को दूर करने के लिए, मैंने पूरी तरह से स्थानीय मॉडलों का उपयोग करके एक RAG आर्किटेक्चर लागू किया है। यह दृष्टिकोण इंटरनेट कनेक्टिविटी की आवश्यकता को समाप्त करता है और सुनिश्चित करता है कि सभी डेटा प्रोसेसिंग और मॉडल इंटरैक्शन संगठन के सुरक्षित आंतरिक सिस्टम के भीतर होते हैं।
एक पूर्व-प्रशिक्षित LLM को स्थानीय रूप से डाउनलोड करना: सबसे सामान्य ओपन-सोर्स LLM Facebook का Llama है।
!wget https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/Phi-3-mini-4k-instruct-q4.gguf
Phi-3-mini-4k-instr 100%[===================>] 2.23G 39.2MB/s in 57s
from langchain import LlamaCpp
llm = LlamaCpp(
model_path="Phi-3-mini-4k-instruct-q4.gguf",
n_gpu_layers=-1,
max_tokens=500,
n_ctx=2048,
seed=42,
verbose=False
)
टेक्स्ट को एम्बेड करने के लिए, BAAI/bge-small-en-v1.5 मॉडल का उपयोग किया जाता है।
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
# Embedding Model for converting text to numerical representations
embedding_model = HuggingFaceEmbeddings(
model_name='BAAI/bge-small-en-v1.5'
)
एक वेक्टर डेटाबेस को एम्बेडिंग मॉडल का उपयोग करके बनाया गया है।
from langchain.vectorstores import FAISS
# Split into a list of sentences
texts = text_article.split('\n')
# Clean up to remove empty spaces and new lines
texts = [t.strip(' \n') for t in texts]
# Create a local vector database
db = FAISS.from_texts(texts, embedding_model)
पिछले कार्यान्वयन के समान, मैंने प्रॉम्प्ट बनाया है ताकि संदर्भ को प्रश्न के साथ प्रदान किया जा सके।
from langchain import PromptTemplate
from langchain.chains import RetrievalQA
# Create a prompt template
template = """<|user|>
Relevant information:
{context}
Provide a concise answer the following question using the relevant information provided above:
{question}<|end|>
<|assistant|>"""
prompt = PromptTemplate(
template=template,
input_variables=["context", "question"]
)
# RAG Pipeline
rag = RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=db.as_retriever(),
chain_type_kwargs={
"prompt": prompt
},
verbose=True
)
प्रश्न का उत्तर है
rag.invoke(query)
1m> Finished chain.
{'query': 'How many years of experience does the candidate have?',
'result': ' The candidate has 7 years of experience in Data Science and Machine learning.'}
RAG मूल्यांकन¶
RAG उत्तरों का मूल्यांकन विभिन्न मानकों पर किया जा सकता है, जैसे प्रवाह, धारित उपयोगिता, उद्धरण पुनः प्राप्ति और सटीकता, विश्वास, प्रासंगिकता और ग्राउंडेडनेस। चलिए प्रासंगिकता और ग्राउंडेडनेस को विस्तार से देखते हैं।
हम LLM-as-a-judge विधि का उपयोग करके RAG प्रणाली की गुणवत्ता की जांच कर सकते हैं।
1. ग्राउंडेडनेस: यदि उत्तर केवल प्रदान किए गए संदर्भ पर आधारित है
2. प्रासंगिकता: यदि उत्तर प्रासंगिक है और प्रश्न के सभी पहलुओं का उत्तर देता है
groundedness_rater_system_message = """
You are tasked with rating AI generated answers to questions posed by users.
You will be presented a question, context used by the AI system to generate the answer and an AI generated answer to the question.
In the input, the question will begin with ###Question, the context will begin with ###Context while the AI generated answer will begin with ###Answer.
Evaluation criteria:
The task is to judge the extent to which the metric is followed by the answer.
1 - The metric is not followed at all
2 - The metric is followed only to a limited extent
3 - The metric is followed to a good extent
4 - The metric is followed mostly
5 - The metric is followed completely
Metric:
The answer should be derived only from the information presented in the context
Instructions:
1. First write down the steps that are needed to evaluate the answer as per the metric.
2. Give a step-by-step explanation if the answer adheres to the metric considering the question and context as the input.
3. Next, evaluate the extent to which the metric is followed.
4. Use the previous information to rate the answer using the evaluaton criteria and assign a score.
"""
groundedness_prompt = [
{'role':'system', 'content': groundedness_rater_system_message},
{'role': 'user', 'content': user_message_template.format(
question=query,
context=agumented_search_context,
answer=prediction
)
}
]
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=groundedness_prompt,
temperature=0
)
print(response.choices[0].message.content)
Steps to evaluate the answer:
1. Identify the specific information in the context related to the candidate's experience.
2. Check if the answer provided matches the exact number of years of experience mentioned in the context.
3. Determine if any additional information not present in the context is included in the answer.
Explanation:
1. The context clearly states that Harsha has 7 years of experience in Data Science and Machine learning.
2. The answer provided states "The candidate has 7 years of experience," which directly matches the information given in the context.
3. The answer does not include any additional information beyond what is provided in the context.
The answer follows the metric completely by accurately stating the number of years of experience the candidate has based on the information given in the context.
### Evaluation: 5
### Score: 5
relevance_rater_system_message = """
You are tasked with rating AI generated answers to questions posed by users.
You will be presented a question, context used by the AI system to generate the answer and an AI generated answer to the question.
In the input, the question will begin with ###Question, the context will begin with ###Context while the AI generated answer will begin with ###Answer.
Evaluation criteria:
The task is to judge the extent to which the metric is followed by the answer.
1 - The metric is not followed at all
2 - The metric is followed only to a limited extent
3 - The metric is followed to a good extent
4 - The metric is followed mostly
5 - The metric is followed completely
Metric:
Relevance measures how well the answer addresses the main aspects of the question, based on the context.
Consider whether all and only the important aspects are contained in the answer when evaluating relevance.
Instructions:
1. First write down the steps that are needed to evaluate the context as per the metric.
2. Give a step-by-step explanation if the context adheres to the metric considering the question as the input.
3. Next, evaluate the extent to which the metric is followed.
4. Use the previous information to rate the context using the evaluaton criteria and assign a score.
"""
relevance_prompt = [
{'role':'system', 'content': relevance_rater_system_message},
{'role': 'user', 'content': user_message_template.format(
question=query,
context=agumented_search_context,
answer=prediction
)
}
]
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=relevance_prompt,
temperature=0
)
print(response.choices[0].message.content)
1. Identify the main aspects of the question: The main aspect of the question is to determine the number of years of experience the candidate has.
2. Look for relevant information in the context: Search for details related to the candidate's experience in the context provided.
3. Determine if the answer contains the specific number of years of experience: Check if the answer explicitly states the number of years of experience the candidate has.
4. Evaluate if the answer addresses the main aspect of the question: Assess whether the answer accurately provides the number of years of experience as requested in the question.
Explanation:
The context clearly states that Harsha has 7 years of experience in Data Science and Machine learning. The AI generated answer directly addresses the main aspect of the question by stating "The candidate has 7 years of experience." The answer is relevant as it provides the specific number of years of experience the candidate has based on the information in the context.
Therefore, the answer follows the metric of relevance completely by addressing the main aspect of the question accurately.
###Final Rating
5 - The metric is followed completely
Written with assistance from Generative AI
References¶
- Hands-On Large Language Models, Chapter 8 - Semantic Search, Jay Alammar & Maarten Grootendorst
- AI Expert Bootcamp, Great Learning