Handling Imbalanced Classes
What are imbalanced classes¶
Imbalanced classes is a significant issue in classification problems. Class imbalance happens when the dependant variable has one class with a higher frequency compared to the lower class. Take an example of the below data.
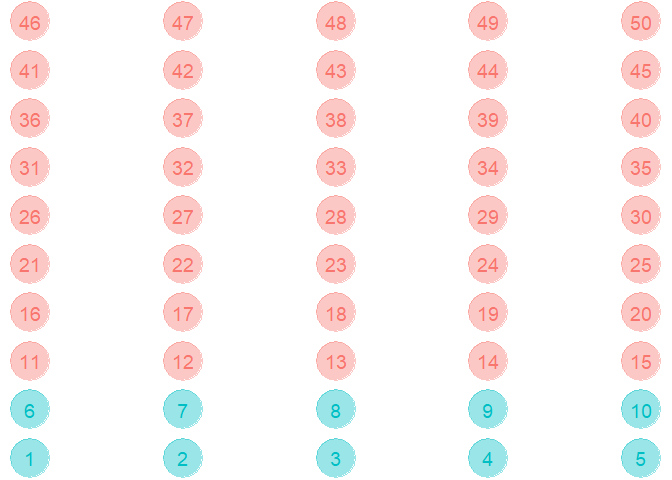
In this data, the class in blue is the minority class with a class imbalance of 10/40 = 25%. Such behaviour is observed in various problems such as:
1. Fraud detection
2. Conversion prediction
3. Spam detection
4. Churn prediction
5. Outlier detection
Each of these problem statements is binary class problems with the minority class having a significantly lower frequency than the majority class. Despite this, the prediction of the minority class is more important.
Why is this a problem?¶
From the above data, we could create a model which predicts the class always as Red. This model will have an accuracy of 75%. If this were fraud detection, for example, then this prediction would be worthless as we would not be predicting any fraud.
In the above example, it is easy to split the data accurately into two classes, i.e. those above 10 are red class and the remaining are blue. This can be done as this data is linearly separable. However, in most cases, if we are using accuracy or AUC for prediction, then we would reach the model that always predicts Red. This can be sometimes resolved by changing the optimising metric to use while training, like sensitivity or specificity, which will be described in another blog. In any case, it is good to balance the classes before training a machine learning model.
How to resolve this issue?¶
Balancing the classes means reducing the imbalance in the data set. This can be achieved in many ways, but three are discussed in this blog. They are: 1. Up-sampling 2. Down-sampling 3. SMOTE sampling
Upsampling¶
In up-sampling, we randomly sample (with replacement) the minority class to be the same size as the majority class. While this retains the full information of both the classes, the size of the data will become much larger. This can cause data handling and speed issues.
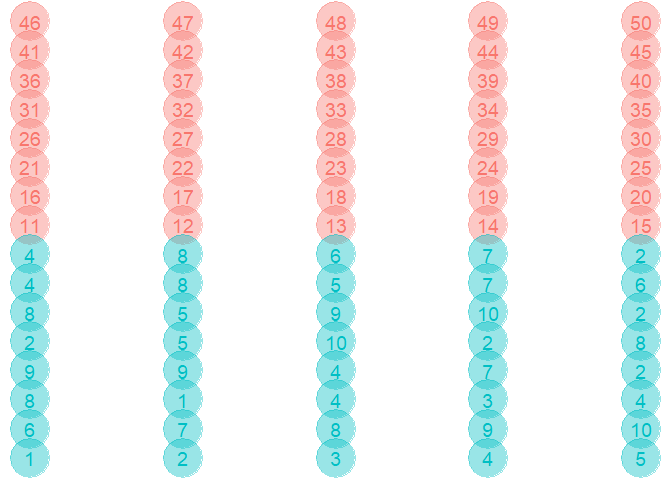
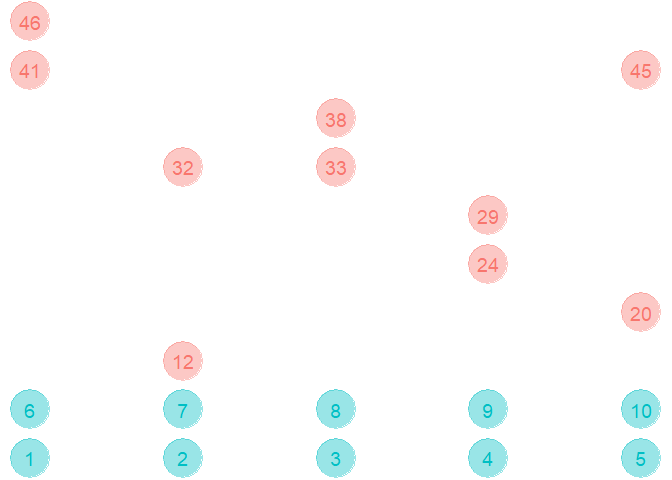
Downsampling¶
In down-sampling, we subset the majority class in such a way that their frequency is similar to the minority class. This will create a smaller data-set which is easier to train, but the information from the majority class can be lost.
SMOTE Sampling¶
SMOTE is a technique which down-sample the majority class and synthesises new data points in the minority class. SMOTE stands for Synthetic Minority Over-sampling Technique. Refer this paper for more.
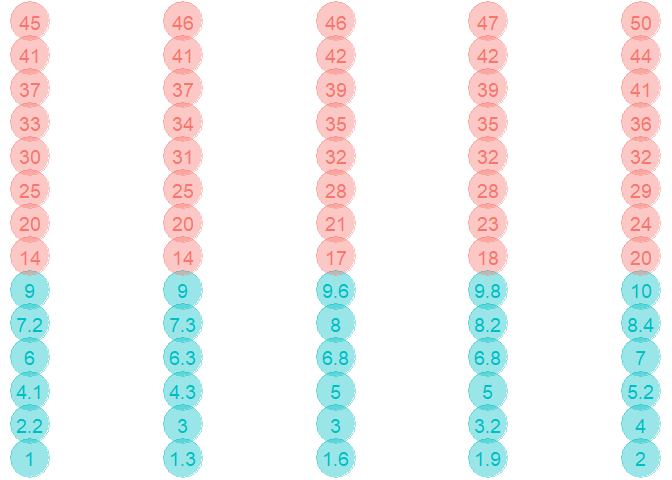
ROSE Sampling¶
ROSE sampling is another synthetic sampling technique which creates synthetic minority and majority classes to handle an imbalance in the dataset. Read this paper for more.

References¶
- Menardi, G., Torelli, N. Training and assessing classification rules with imbalanced data. Data Min Knowl Disc 28, 92–122 (2014).
- Chawla, N.V., Bowyer, K.W., Hall, L.O. and Kegelmeyer, W.P., 2002. SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16, pp.321-357.
- Caret documentation: https://topepo.github.io/caret/subsampling-for-class-imbalances.html