Visualizalising tabular data (Airbnb)¶
Author: Achyuthuni Sri Harsha
In this visualistion, we look at various visualisation types on data type tables.
Matplotlib is the most popular library for viz in Python. Seaborn is built on top of it with integrated analysis, specialized plots, and pretty good integration with Pandas. Plotly express is another library for viz.
Also see the full gallery of Seaborn or Matplotlib.
#disable some annoying warnings
import warnings
warnings.filterwarnings('ignore', category=FutureWarning)
#plots the figures in place instead of a new window
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import pandas as pd
import numpy as np
In this blog, we are going to look into the Airbnb data for London. We will look at some trends, patterns and effect of seasonality on the data.
First, let us ponder over the popularity of Airbnb over time. The popularity is proportional to the number of reviews. Importing the reviews dataset:
reviews = pd.read_csv('reviews.csv.gz', parse_dates=['date'])
reviews.head()
| listing_id | id | date | reviewer_id | reviewer_name | comments | |
|---|---|---|---|---|---|---|
| 0 | 11551 | 30672 | 2010-03-21 | 93896 | Shar-Lyn | The flat was bright, comfortable and clean and... |
| 1 | 11551 | 32236 | 2010-03-29 | 97890 | Zane | We stayed with Adriano and Valerio for a week ... |
| 2 | 11551 | 41044 | 2010-05-09 | 104133 | Chase | Adriano was a fantastic host. We felt very at ... |
| 3 | 11551 | 48926 | 2010-06-01 | 122714 | John & Sylvia | We had a most wonderful stay with Adriano and ... |
| 4 | 11551 | 58352 | 2010-06-28 | 111543 | Monique | I'm not sure which of us misunderstood the s... |
Scatter plot¶
To find the number of reviews, we add the total reviews every day, and we then plot it across time as a scatter plot.
fs, axs = plt.subplots(1, figsize=(15,10))
plt.title("Airbnb London: Number of reviews across time", fontsize=30)
reviews.groupby('date').aggregate({'listing_id':'count'}).reset_index().plot.scatter(x = 'date', y = 'listing_id', alpha = 0.25, ax = axs)
axs.set_ylabel('Number of reviews', fontsize=20)
axs.set_xlabel('Time', fontsize=20)
plt.show()
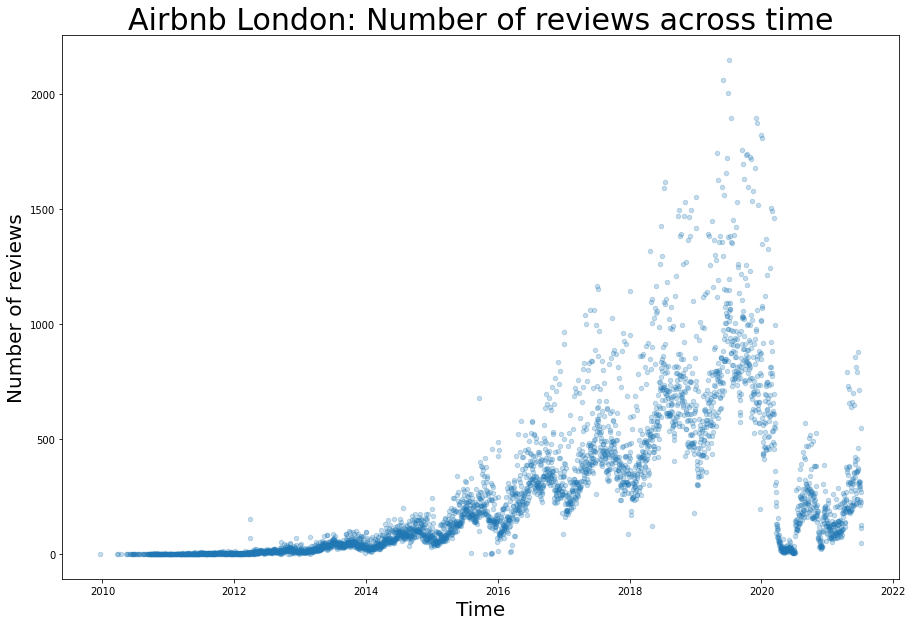
From this plot, we can observe the following:
1. There is an exponential growth in the business pre-pandemic and this has a sudden drop after Covid related restrictions started.
2. Seasonality within every year is visible
To expand n these trends, we should zoom in two sections of the plot. First we should find the seasonality and trend of the data, and then zoom into one of the pre-pandemic year to elaborate on the seasonality. Second, we can zoom into 2020-21 to identify the patterns from covid related lockdowns.
# getting the total number of reviews per day
reviews_time = reviews.groupby('date').aggregate({'listing_id':'count'}).reset_index()
reviews_time['year'] = reviews_time.date.dt.year
# Pre covid data
reviews_time_proper = reviews_time[(reviews_time.year < 2020)]
We can find seasonality and trend within the pre-pandemic data by using decomposition (not explained in this blog). Splitting the data into trend, seasonal and random component, gives me the following:
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(reviews_time_proper.listing_id, model='additive', period = 365)
print(result.plot())
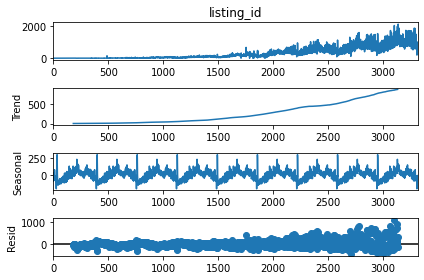
We can see an exponential trend and a repeating constant seasonality within the data. Identifying and predicting pre-pandemic trend and predicting for 2020-21.
y_values = result.trend[182:3136]
x_values = range(182, 3136)
coeffs = np.polyfit(x_values, y_values, 2)
poly_eqn = np.poly1d(coeffs)
y_hat = poly_eqn(range(365, len(reviews_time[reviews_time.year < 2020])))
y_hat1 = poly_eqn(range(len(reviews_time[reviews_time.year < 2020]), len(reviews_time)))
Approximating the seasonality by using a polynomial equation.
y_values = reviews_time[reviews_time.year == 2019].listing_id
x_values = range(365)
coeffs = np.polyfit(x_values, y_values, 15)
poly_eqn = np.poly1d(coeffs)
y_hat_seasonal = poly_eqn(range(365))
Approximating the pattern in 2020-21 with a polynomial equation.
reviews_covid = reviews_time[reviews_time.year >= 2020]
y_values = reviews_covid.listing_id
x_values = range(len(reviews_covid.listing_id))
coeffs = np.polyfit(x_values, y_values, 17)
poly_eqn = np.poly1d(coeffs)
y_hat_covid = poly_eqn(range(25, len(reviews_covid.listing_id)-15))
from mpl_toolkits.axes_grid1.inset_locator import mark_inset, inset_axes
from matplotlib.patches import ConnectionPatch # making lines from top lot to below plot
# Two plots, the main on the top with height 20 inches and the bottom one is 10 inches.
fs, axs = plt.subplots(2, figsize=(20,30), gridspec_kw={'height_ratios': [2, 1]}, constrained_layout=True)
# Title
plt.suptitle("Airbnb London: Number of reviews across time", fontsize=30)
# First plot, main scatterplot
reviews.groupby('date').aggregate({'listing_id':'count'}).\
reset_index().plot.scatter(x = 'date', y = 'listing_id', alpha = 0.25, ax = axs[0])
# adding the trend lines
axs[0].plot(reviews_time[365:len(reviews_time[reviews_time.year < 2020])].date,y_hat, color='red')
axs[0].plot(reviews_time[len(reviews_time[reviews_time.year < 2020]):].date,y_hat1, color='red', linestyle='dashed')
# Modifying the labels and title
axs[0].set_ylabel('Number of reviews', fontsize=15)
axs[0].set_xlabel('Time', fontsize=15)
axs[0].set_title('Total reviews of all types of rooms across London. A trend line is plotted taking the exponential growth of the business before Covid 19 and projecting the same trend during Covid. \n'+
'Seasonality before Covid is shown by zooming for 2019 (sample year). The affect of covid related lockdowns is also shown by zooming from 2020 onwards.',
fontsize=15, loc='left')
# Plotting the data within 2019 as a semantic zooming
axins = inset_axes(axs[0], 8, 5, loc=2, bbox_to_anchor=(0.15, 0.925),
bbox_transform=axs[0].figure.transFigure)
# Semantic zooming plot, scatterplot
reviews.groupby('date').aggregate({'listing_id':'count'}).reset_index().\
plot.scatter(x = 'date', y = 'listing_id', alpha = 0.5, ax = axins)
#adding the trend lines, labels and title
plt.plot(reviews_time[reviews_time.year == 2019].date,y_hat_seasonal, color='red')
plt.ylabel('Number of reviews', fontsize=15)
plt.xlabel('Date', fontsize=15)
plt.title('Sesonality in a year (before COVID 19)', fontsize=20)
# Seasonality plot x and y limits
x1 = min(reviews_time[reviews_time.year == 2019].date)
x2 = max(reviews_time[reviews_time.year == 2019].date)
axins.set_xlim(x1, x2)
axins.set_ylim(0, 2000)
mark_inset(axs[0], axins, loc1=1, loc2=3, fc="none", ec="0.5")
# Second plot
x1 = min(reviews_time[reviews_time.year == 2020].date)
x2 = max(reviews_time[reviews_time.year >= 2020].date)
reviews_time[reviews_time.year >= 2020].plot.scatter(x = 'date', y = 'listing_id', alpha = 0.75, ax = axs[1])
axs[1].set_ylabel('Number of reviews', fontsize=15)
axs[1].set_xlabel('Date', fontsize=15)
axs[1].set_ylim(0, 1200)
axs[1].set_xlim(x1, x2)
axs[1].set_title('Effect of Covid19 on number of reviews', fontsize=20)
axs[1].plot(reviews_covid.date[25:-15],y_hat_covid, color='red')
# Adding annotations in the plot
axs[1].annotate(
text = 'First Covid 19 advisory \n 3-16-2020', # the text
xy=('3-16-2020', 500), #what to annotate
xytext=('3-16-2020', 700), # where the text should be
arrowprops=dict(arrowstyle="->",
connectionstyle="angle3,angleA=-90,angleB=0"),
fontsize=15
)
axs[1].annotate(
'First Lockdown \n 3-23-2020',
xy=('3-23-2020', 350),
xytext=('5-10-2020', 600),
arrowprops=dict(arrowstyle="->"),
fontsize=15
)
axs[1].annotate(
'Easing restrictions \n 7-4-2020',
xy=('7-4-2020', 50),
xytext=('6-15-2020', 700),
arrowprops=dict(arrowstyle="->"),
fontsize=15
)
axs[1].annotate(
'Restrictions eased further \n 8-14-2020',
xy=('8-14-2020', 250),
xytext=('8-1-2020', 600),
arrowprops=dict(arrowstyle="->"),
fontsize=15
)
axs[1].annotate(
'Second Lockdown \n 10-31-2020',
xy=('10-31-2020', 165),
xytext=('10-1-2020', 700),
arrowprops=dict(arrowstyle="->"),
fontsize=15
)
axs[1].annotate(
'Easing restrictions \n 12-2-2020',
xy=('12-2-2020', 120),
xytext=('11-10-2020', 600),
arrowprops=dict(arrowstyle="->"),
fontsize=15
)
axs[1].annotate(
'Christmas \n 12-25-2020',
xy=('12-25-2020', 160),
xytext=('12-25-2020', 700),
arrowprops=dict(arrowstyle="->"),
fontsize=15
)
axs[1].annotate(
'Third Lockdown \n 1-6-2021',
xy=('1-6-2021', 140),
xytext=('1-20-2021', 600),
arrowprops=dict(arrowstyle="->"),
fontsize=15
)
axs[1].annotate(
'Schools reopen \n 3-8-2021',
xy=('3-8-2021', 125),
xytext=('2-25-2021', 700),
arrowprops=dict(arrowstyle="->"),
fontsize=15
)
axs[1].annotate(
'All restrictions removed \n 6-21-2021',
xy=('6-21-2021', 400),
xytext=('5-21-2021', 700),
arrowprops=dict(arrowstyle="->"),
fontsize=15
)
axs[1].annotate(
'Non essentials reopen \n 4-12-2021',
xy=('4-12-2021', 270),
xytext=('4-1-2021', 600),
arrowprops=dict(arrowstyle="->"),
fontsize=15
)
# plotting the connections between the two plots
con = ConnectionPatch(xyA=(x1,-105), xyB=(x1,1200), coordsA="data", coordsB="data",
axesA=axs[0], axesB=axs[1])
axs[1].add_artist(con)
# con = ConnectionPatch(axesA=axs[0], axesB=axs[1])
con = ConnectionPatch(xyA=(x2,-105), xyB=(x2,1200), coordsA="data", coordsB="data",
axesA=axs[0], axesB=axs[1])
axs[1].add_artist(con)
plt.show()
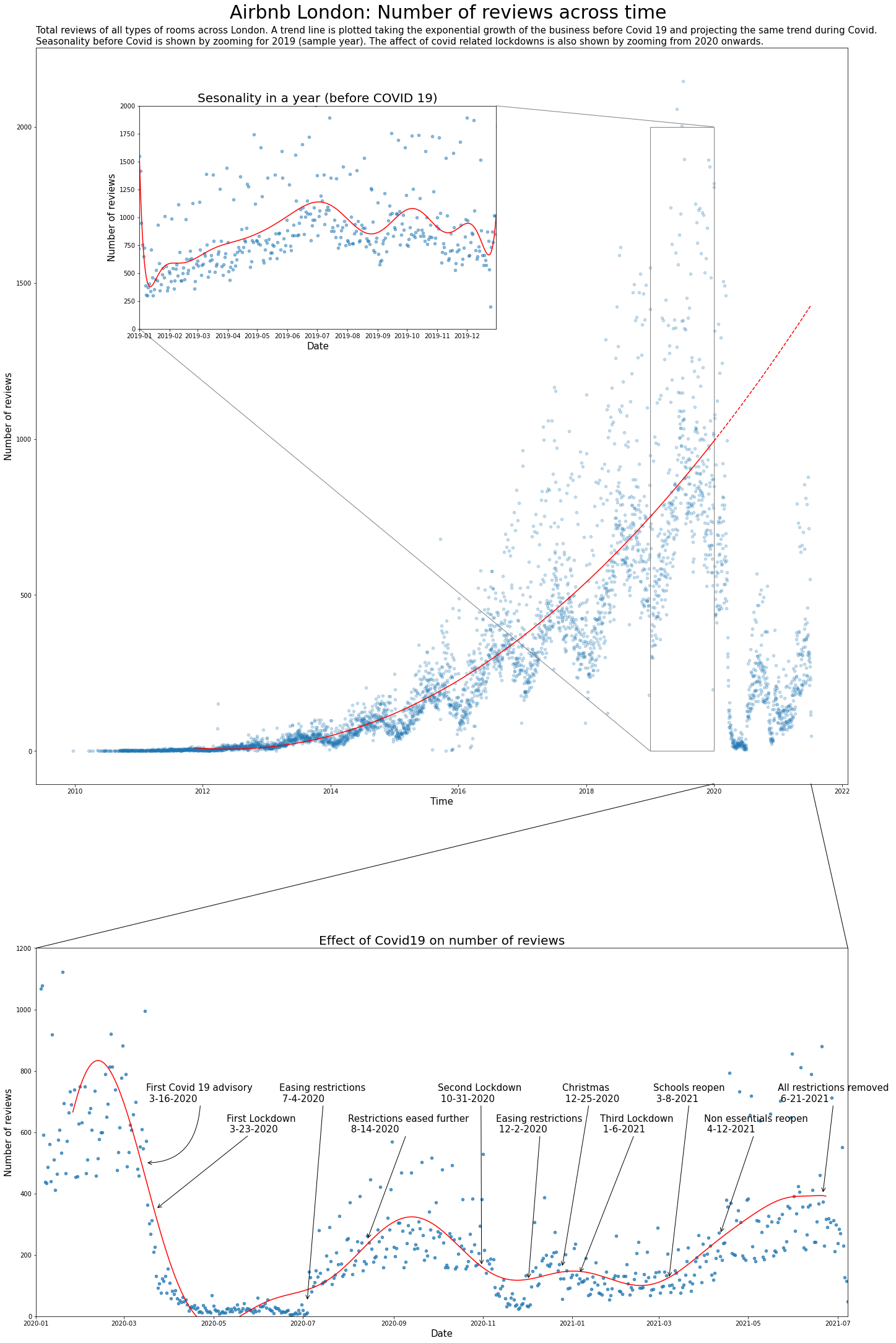
From this plot, we can see the following:
1. The variation of the reviews across time and the trend before the pandemic are captured. The trend is extrapolated to 2020-21 to show the growth that could have happened if not for the pandemic.
2. Seasonality within the data is shown by semantic zooming into one sample year. We can see how Airbnb is more popular in July, September and January.
3. We can also see the effect of the pandemic on the number of reviews. We can observe a sharp decline in the first few months of 2020, and then how lockdowns and openings have affected the total number of reviews.
Sunburst and pie charts¶
Let us now deep dive into the data and look at the type of listings and locations that have contributed to this growth. Importing the complete listings dataset.
listing_detailed = pd.read_csv('listings.csv.gz')
pd.options.display.max_columns = None # to show all the columns
listing_detailed.head()
| id | listing_url | scrape_id | last_scraped | name | description | neighborhood_overview | picture_url | host_id | host_url | host_name | host_since | host_location | host_about | host_response_time | host_response_rate | host_acceptance_rate | host_is_superhost | host_thumbnail_url | host_picture_url | host_neighbourhood | host_listings_count | host_total_listings_count | host_verifications | host_has_profile_pic | host_identity_verified | neighbourhood | neighbourhood_cleansed | neighbourhood_group_cleansed | latitude | longitude | property_type | room_type | accommodates | bathrooms | bathrooms_text | bedrooms | beds | amenities | price | minimum_nights | maximum_nights | minimum_minimum_nights | maximum_minimum_nights | minimum_maximum_nights | maximum_maximum_nights | minimum_nights_avg_ntm | maximum_nights_avg_ntm | calendar_updated | has_availability | availability_30 | availability_60 | availability_90 | availability_365 | calendar_last_scraped | number_of_reviews | number_of_reviews_ltm | number_of_reviews_l30d | first_review | last_review | review_scores_rating | review_scores_accuracy | review_scores_cleanliness | review_scores_checkin | review_scores_communication | review_scores_location | review_scores_value | license | instant_bookable | calculated_host_listings_count | calculated_host_listings_count_entire_homes | calculated_host_listings_count_private_rooms | calculated_host_listings_count_shared_rooms | reviews_per_month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 11551 | https://www.airbnb.com/rooms/11551 | 20210706215658 | 2021-07-08 | Arty and Bright London Apartment in Zone 2 | Unlike most rental apartments my flat gives yo... | Not even 10 minutes by metro from Victoria Sta... | https://a0.muscache.com/pictures/b7afccf4-18e5... | 43039 | https://www.airbnb.com/users/show/43039 | Adriano | 2009-10-03 | London, England, United Kingdom | Hello, I'm a friendly Italian man with a posit... | within an hour | 100% | 85% | f | https://a0.muscache.com/im/pictures/user/5f182... | https://a0.muscache.com/im/pictures/user/5f182... | Brixton | 0.0 | 0.0 | ['email', 'phone', 'reviews', 'jumio', 'offlin... | t | t | London, United Kingdom | Lambeth | NaN | 51.46095 | -0.11758 | Entire apartment | Entire home/apt | 4 | NaN | 1 bath | 1.0 | 3.0 | ["Hot water", "Hair dryer", "Smoke alarm", "Fi... | $99.00 | 2 | 1125 | 2.0 | 2.0 | 1125.0 | 1125.0 | 2.0 | 1125.0 | NaN | t | 0 | 30 | 58 | 290 | 2021-07-08 | 193 | 1 | 0 | 2011-10-11 | 2018-04-29 | 4.57 | 4.62 | 4.58 | 4.78 | 4.85 | 4.53 | 4.52 | NaN | f | 3 | 3 | 0 | 0 | 1.63 |
| 1 | 13913 | https://www.airbnb.com/rooms/13913 | 20210706215658 | 2021-07-08 | Holiday London DB Room Let-on going | My bright double bedroom with a large window h... | Finsbury Park is a friendly melting pot commun... | https://a0.muscache.com/pictures/miso/Hosting-... | 54730 | https://www.airbnb.com/users/show/54730 | Alina | 2009-11-16 | London, England, United Kingdom | I am a Multi-Media Visual Artist and Creative ... | within a few hours | 100% | 100% | f | https://a0.muscache.com/im/users/54730/profile... | https://a0.muscache.com/im/users/54730/profile... | LB of Islington | 3.0 | 3.0 | ['email', 'phone', 'facebook', 'reviews', 'off... | t | t | Islington, Greater London, United Kingdom | Islington | NaN | 51.56861 | -0.11270 | Private room in apartment | Private room | 2 | NaN | 1 shared bath | 1.0 | 0.0 | ["Host greets you", "Dryer", "Hot water", "Sha... | $65.00 | 1 | 29 | 1.0 | 1.0 | 29.0 | 29.0 | 1.0 | 29.0 | NaN | t | 30 | 60 | 90 | 365 | 2021-07-08 | 21 | 0 | 0 | 2011-07-11 | 2011-09-13 | 4.85 | 4.79 | 4.84 | 4.79 | 4.89 | 4.63 | 4.74 | NaN | f | 2 | 1 | 1 | 0 | 0.17 |
| 2 | 15400 | https://www.airbnb.com/rooms/15400 | 20210706215658 | 2021-07-08 | Bright Chelsea Apartment. Chelsea! | Lots of windows and light. St Luke's Gardens ... | It is Chelsea. | https://a0.muscache.com/pictures/428392/462d26... | 60302 | https://www.airbnb.com/users/show/60302 | Philippa | 2009-12-05 | Kensington, England, United Kingdom | English, grandmother, I have travelled quite ... | NaN | NaN | NaN | f | https://a0.muscache.com/im/users/60302/profile... | https://a0.muscache.com/im/users/60302/profile... | Chelsea | 1.0 | 1.0 | ['email', 'phone', 'reviews', 'jumio', 'govern... | t | t | London, United Kingdom | Kensington and Chelsea | NaN | 51.48780 | -0.16813 | Entire apartment | Entire home/apt | 2 | NaN | 1 bath | 1.0 | 1.0 | ["Dryer", "Hot water", "Shampoo", "Hair dryer"... | $75.00 | 10 | 50 | 10.0 | 10.0 | 50.0 | 50.0 | 10.0 | 50.0 | NaN | t | 0 | 14 | 44 | 319 | 2021-07-08 | 89 | 0 | 0 | 2012-07-16 | 2019-08-10 | 4.79 | 4.84 | 4.88 | 4.87 | 4.82 | 4.93 | 4.73 | NaN | t | 1 | 1 | 0 | 0 | 0.81 |
| 3 | 17402 | https://www.airbnb.com/rooms/17402 | 20210706215658 | 2021-07-08 | Superb 3-Bed/2 Bath & Wifi: Trendy W1 | You'll have a wonderful stay in this superb mo... | Location, location, location! You won't find b... | https://a0.muscache.com/pictures/39d5309d-fba7... | 67564 | https://www.airbnb.com/users/show/67564 | Liz | 2010-01-04 | Brighton and Hove, England, United Kingdom | We are Liz and Jack. We manage a number of ho... | within a day | 70% | 90% | f | https://a0.muscache.com/im/users/67564/profile... | https://a0.muscache.com/im/users/67564/profile... | Fitzrovia | 18.0 | 18.0 | ['email', 'phone', 'reviews', 'jumio', 'offlin... | t | t | London, Fitzrovia, United Kingdom | Westminster | NaN | 51.52195 | -0.14094 | Entire apartment | Entire home/apt | 6 | NaN | 2 baths | 3.0 | 3.0 | ["Dryer", "Hot water", "Shampoo", "Hair dryer"... | $307.00 | 4 | 365 | 4.0 | 4.0 | 365.0 | 365.0 | 4.0 | 365.0 | NaN | t | 6 | 6 | 17 | 218 | 2021-07-08 | 43 | 1 | 1 | 2011-09-18 | 2019-11-02 | 4.69 | 4.80 | 4.68 | 4.66 | 4.66 | 4.85 | 4.59 | NaN | f | 15 | 15 | 0 | 0 | 0.36 |
| 4 | 17506 | https://www.airbnb.com/rooms/17506 | 20210706215658 | 2021-07-08 | Boutique Chelsea/Fulham Double bed 5-star ensuite | Enjoy a chic stay in this elegant but fully mo... | Fulham is 'villagey' and residential – a real ... | https://a0.muscache.com/pictures/11901327/e63d... | 67915 | https://www.airbnb.com/users/show/67915 | Charlotte | 2010-01-05 | London, England, United Kingdom | Named best B&B by The Times. Easy going hosts,... | NaN | NaN | NaN | f | https://a0.muscache.com/im/users/67915/profile... | https://a0.muscache.com/im/users/67915/profile... | Fulham | 3.0 | 3.0 | ['email', 'phone', 'jumio', 'selfie', 'governm... | t | t | London, United Kingdom | Hammersmith and Fulham | NaN | 51.47935 | -0.19743 | Private room in townhouse | Private room | 2 | NaN | 1 private bath | 1.0 | 1.0 | ["Air conditioning", "Carbon monoxide alarm", ... | $150.00 | 3 | 21 | 3.0 | 3.0 | 21.0 | 21.0 | 3.0 | 21.0 | NaN | t | 29 | 59 | 89 | 364 | 2021-07-08 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | f | 2 | 0 | 2 | 0 | NaN |
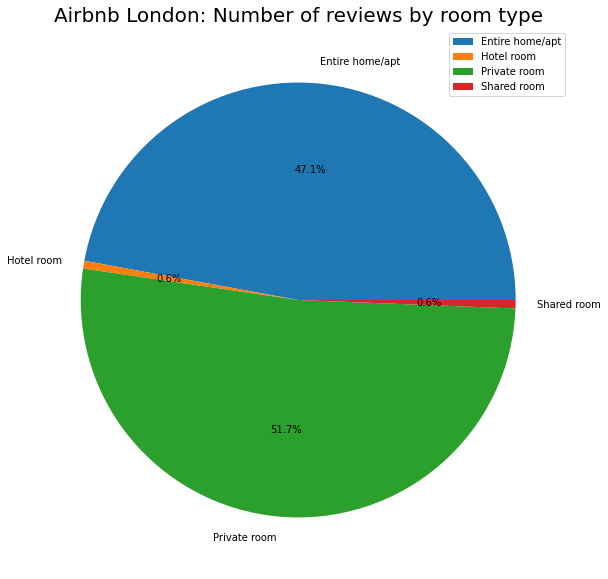
Looking at the number of reviews by room type and by location, we have:
listing_detailed.groupby('room_type').\
aggregate({'number_of_reviews':'sum'}).\
plot.pie(y='number_of_reviews', figsize=(10, 10),
autopct='%1.1f%%' # to add the percentages text
)
plt.ylabel("")
plt.title("Airbnb London: Number of reviews by room type", fontsize=20)
plt.show()
# Function to combine last few classes ito one class
total_other_reviews = 0
def combine_last_n(df):
df1 = df.copy()
global total_other_reviews
total_other_reviews = (sum(df[df.number_of_reviews <= 5000].number_of_reviews))
df1.loc[df.number_of_reviews <= 10000, 'number_of_reviews'] = 0
return df1.number_of_reviews
listing_detailed.groupby('neighbourhood_cleansed').\
aggregate({'number_of_reviews':'sum'}).\
sort_values('number_of_reviews', ascending = False).\
assign(no_reviews_alt = combine_last_n).\
append(pd.Series({'number_of_reviews': 0, 'no_reviews_alt':total_other_reviews}, name='Others')).\
plot.pie(y='no_reviews_alt', figsize=(10, 10), legend=None, rotatelabels=True,
wedgeprops=dict(width=.5) # for donut shape
)
plt.ylabel("")
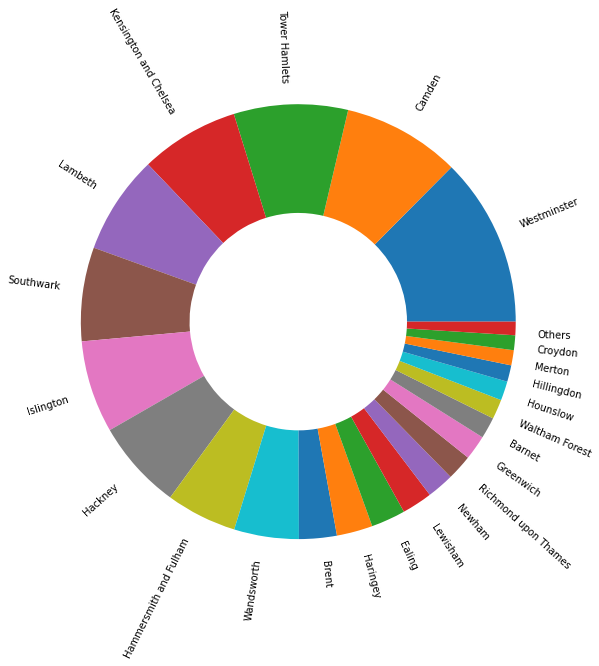
We can see that private room is the most popular with the most number of reviews followed by entire home/apt. The others are insignificant. Similarly, Westminster and Camden are the top two locations in London. Using a sunburst chart, we can look at these two combined.
listings_sunburst = listing_detailed.groupby(['room_type', 'neighbourhood_cleansed']).\
aggregate({'number_of_reviews':'sum'}).\
sort_values('number_of_reviews', ascending = False).reset_index()
fig = px.sunburst(listings_sunburst, path=['room_type', 'neighbourhood_cleansed'], values='number_of_reviews',
hover_data = ['room_type', 'number_of_reviews'], hover_name = 'neighbourhood_cleansed',
title = 'Airbnb London: Popularity sunburst chart', width = 900, height = 900)
fig.show()
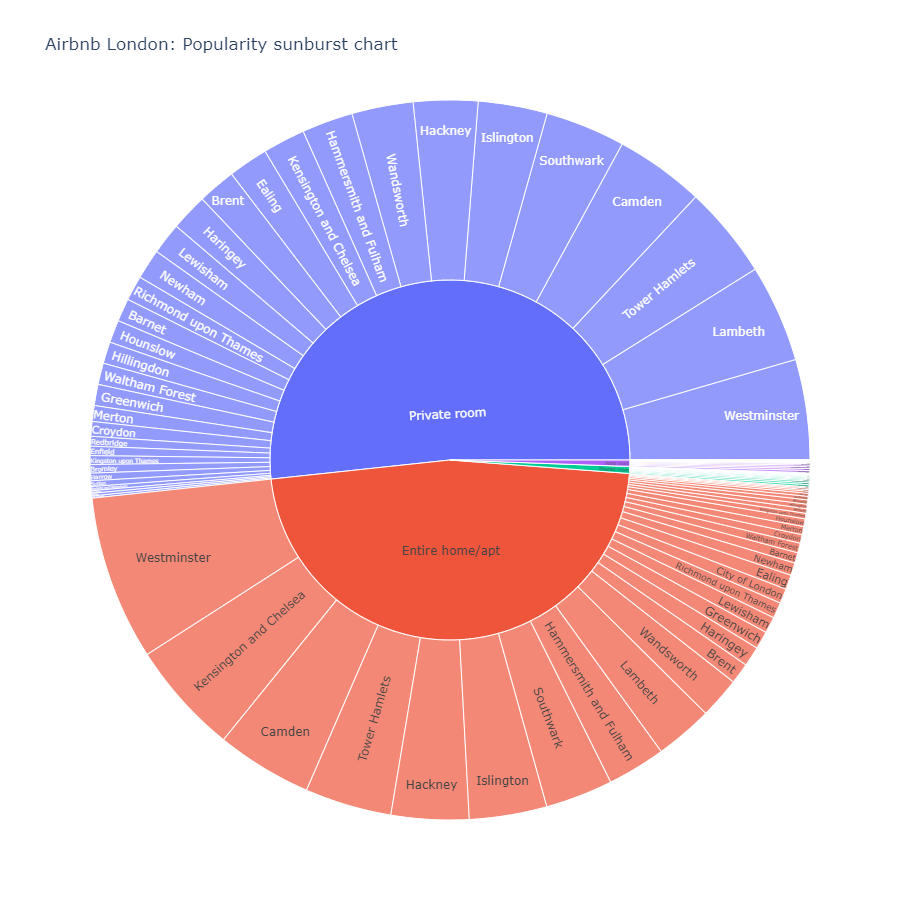
Parallel Coordinates¶
From this chart, we can see that Westminster is the most popular location for all the room types, the second and the third popular are different for different room types. Let us take Kensington and Chelsea for example, we can see the ranking of this area in every room type using a parallel coordinates plot.
top_20_names = list(listings_sunburst.sort_values('number_of_reviews', ascending = False).head(30)['neighbourhood_cleansed'])
listings_sunburst_wide = listings_sunburst.\
pivot(index='neighbourhood_cleansed', columns='room_type', values='number_of_reviews').reset_index()
listings_sunburst_wide = listings_sunburst_wide.replace(np.nan, 0)
fig = px.parallel_coordinates(
listings_sunburst_wide
)
# add the pink line to highlight Kensington
fig.data[0]['dimensions'][0]['constraintrange'] = [50000, 60000]
fig.update_layout(title_text='Kensington and Chelsea (in blue) popularity ranking across room types', title_x=0.7, title_y = 0.05)
fig.show()
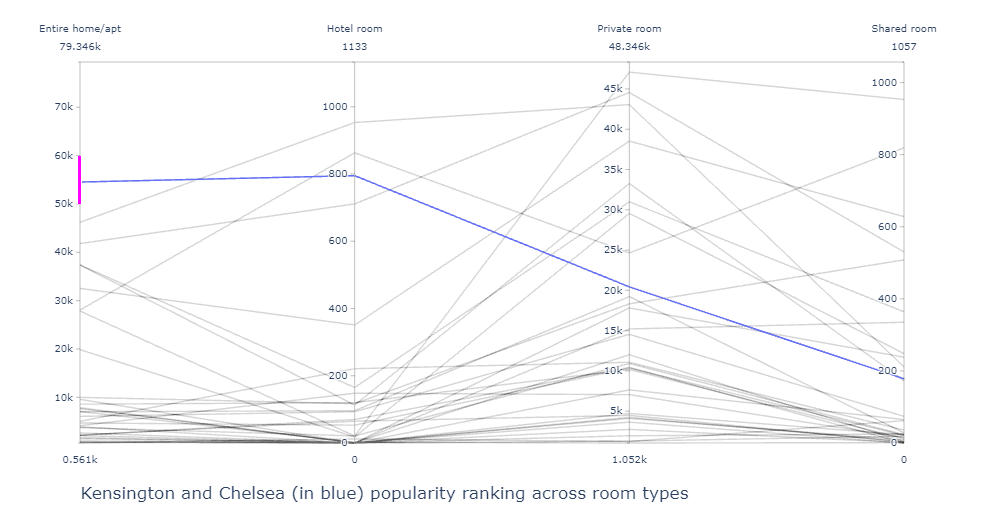
From this chart we can see how Kensington (highlighted in Blue) is in top 2 for 'Entire Home Apartment' while it's not in the top 5 for shared room. This chart, along with the sunburst above shows what type of locations are popular for different room types.
Bar chart and Steam graphs¶
How does this ratio between the popularities change with time? One way to see this is using a stacked bar chart.
reviews_detailed = pd.merge(listing_detailed[['id', 'neighbourhood_cleansed', 'room_type']], reviews, left_on = 'id', right_on = 'listing_id')
fs, axs = plt.subplots(1, figsize=(15,10))
reviews_detailed['year'] = reviews_detailed.date.dt.year
reviews_detailed.groupby(['year', 'room_type']).\
aggregate({'listing_id':'count'}).\
unstack().reset_index().\
plot.bar(x = 'year', y = 'listing_id', ax = axs, stacked = True)
plt.title('Popularity of different rooms across the years', fontsize = 25)
plt.legend(loc='upper right', title="Type of room", fontsize='medium',fancybox=True)
axs.set_ylabel('Number of reviews', fontsize=20)
axs.set_xlabel('Years', fontsize=20)
plt.show()
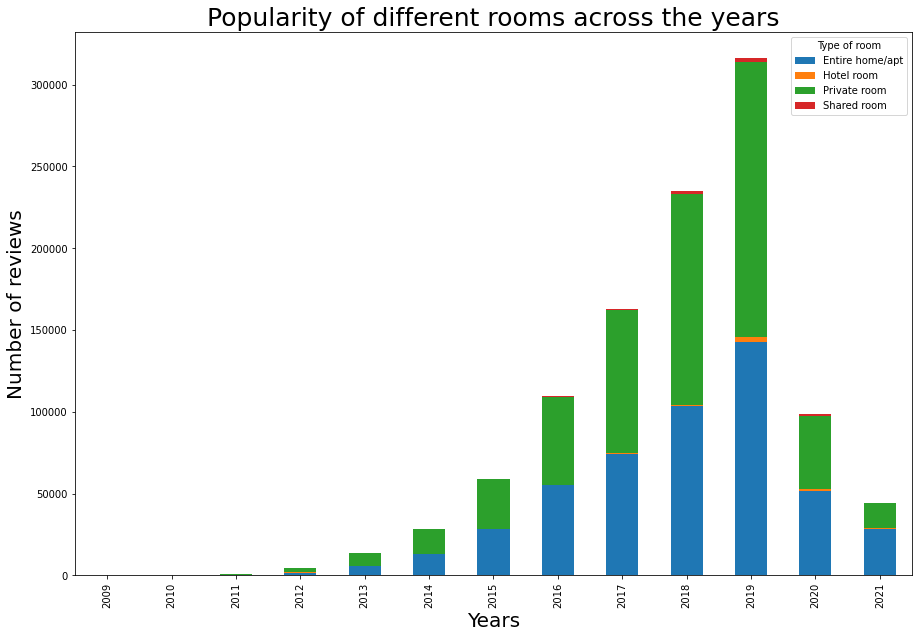
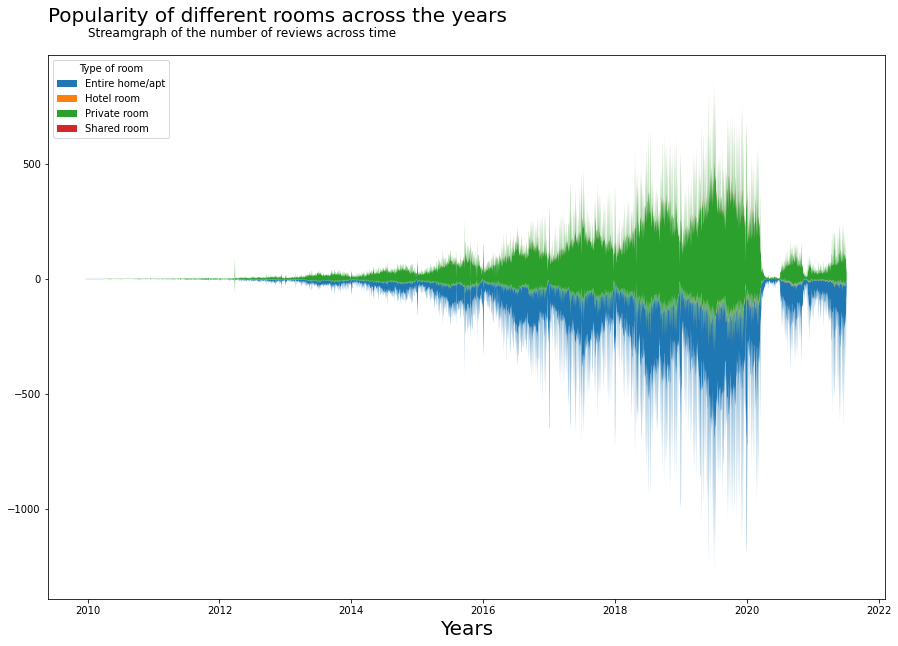
From this bar chart we can see the same increase that we have seen in the scatter plot, that is an exponential increase till 2019, and a subsequent decrease due to the pandemic. Another cool way to look at this is by looking at streamgraphs. In streamgraph, we can see the effect of seasonality within the classes.
fs, ax = plt.subplots(1, figsize=(15,10))
reviews_room = reviews_detailed.groupby(['date', 'room_type']).\
aggregate({'listing_id':'count'}).\
unstack().reset_index()
reviews_room.columns = ['date', 'Entire home/apt', 'Hotel room', 'Private room', 'Shared room']
ax.stackplot(reviews_room.date,
list(reviews_room[['Entire home/apt', 'Hotel room', 'Private room', 'Shared room']].fillna(0).\
to_numpy().transpose()),
baseline='wiggle')
plt.title('Popularity of different rooms across the years', fontsize=20, y=1.05,loc='left')
ax.text("2010",1050,'Streamgraph of the number of reviews across time',ha='left', fontsize=12)
plt.legend(['Entire home/apt', 'Hotel room', 'Private room', 'Shared room'], loc='upper left', title="Type of room")
ax.set_xlabel('Years', fontsize=20)
plt.show()
Heatmap¶
Which locations are better, and which locations should improve on their rating? We can find the average rating across the location by averaging out the rating for each host within the location.
location_rating = listing_detailed.groupby(['neighbourhood_cleansed', 'room_type']).\
aggregate({'review_scores_rating':'mean'}).unstack().reset_index()
location_rating.columns = ['neighbourhood', 'Entire home/apt', 'Hotel room', 'Private room', 'Shared room']
location_rating.index = location_rating.neighbourhood
One of the ways to visualise the average rating is using a heatmap.
fig, ax = plt.subplots(figsize=[20,len(location_rating)/3.3])
sns.heatmap(data=location_rating[['Entire home/apt', 'Hotel room', 'Private room', 'Shared room']],
annot=False, cbar_kws={"shrink":0.5,"orientation":'vertical'},linewidths=0.004,linecolor='grey',vmin=0,vmax=5, center = 0.25)
plt.show()

Although this heatmap presents us the with the average ratings per borough, we can further add the following details for clarity:
1. Location of the borough in London (e.g.: Central London)
2. Arranged from the best rated to the worst rated boroughs within each location
3. Proper colour selection based on scale and human rating psychology : Average human ratings below 2.5 means bad rating and above 4.5 means very good rating (out of 5). It is more natural to use a diverging red-green scale for displaying negative-positive relationship.
def add_regions(df, borough_col_name):
"""
This function takes as input a dataframe with a column which includes London's borough name
Then returns the same dataframw with sub regions names added for each borough
"""
central = ['Camden', 'City of London', 'Kensington and Chelsea', 'Islington', 'Lambeth', 'Southwark', 'Westminster']
east = ['Barking and Dagenham', 'Bexley', 'Greenwich', 'Hackney', 'Havering', 'Lewisham', 'Newham', 'Redbridge', 'Tower Hamlets', 'Waltham Forest']
north = ['Barnet', 'Enfield', 'Haringey']
south = ['Bromley', 'Croydon', 'Kingston upon Thames', 'Merton', 'Sutton', 'Wandsworth']
west = ['Brent', 'Ealing', 'Hammersmith and Fulham', 'Harrow', 'Richmond upon Thames', 'Hillingdon', 'Hounslow']
df['sub_regions'] = np.where((df[borough_col_name] == central[0]) |
(df[borough_col_name] == central[1]) |
(df[borough_col_name] == central[2]) |
(df[borough_col_name] == central[3]) |
(df[borough_col_name] == central[4]) |
(df[borough_col_name] == central[5]) |
(df[borough_col_name] == central[6])
, 'Central', 'no')
df['sub_regions'] = np.where((df[borough_col_name] == east[0]) |
(df[borough_col_name] == east[1]) |
(df[borough_col_name] == east[2]) |
(df[borough_col_name] == east[3]) |
(df[borough_col_name] == east[4]) |
(df[borough_col_name] == east[5]) |
(df[borough_col_name] == east[6]) |
(df[borough_col_name] == east[7]) |
(df[borough_col_name] == east[8]) |
(df[borough_col_name] == east[9])
, 'East', df['sub_regions'])
df['sub_regions'] = np.where((df[borough_col_name] == north[0]) |
(df[borough_col_name] == north[1]) |
(df[borough_col_name] == north[2])
, 'North', df['sub_regions'])
df['sub_regions'] = np.where((df[borough_col_name] == south[0]) |
(df[borough_col_name] == south[1]) |
(df[borough_col_name] == south[2]) |
(df[borough_col_name] == south[3]) |
(df[borough_col_name] == south[4]) |
(df[borough_col_name] == south[5])
, 'South', df['sub_regions'])
df['sub_regions'] = np.where((df[borough_col_name] == west[0]) |
(df[borough_col_name] == west[1]) |
(df[borough_col_name] == west[2]) |
(df[borough_col_name] == west[3]) |
(df[borough_col_name] == west[4]) |
(df[borough_col_name] == west[5]) |
(df[borough_col_name] == west[6])
, 'West', df['sub_regions'])
return df
def sort_data(df):
"""
Groups the data by location and sorts the data based on average rating within the location.
Different locations are sorted by average rating.
"""
df1 = df.copy()
df1['average_rating'] = (df1['Entire home/apt']+ df1['Hotel room'] + df1['Private room']+df1['Shared room'])/4
df1['location_average'] = df1.groupby('sub_regions')['average_rating'].transform('mean')
df1 = df1.sort_values(['location_average', 'average_rating'], ascending=False)
return df1[['Private room', 'Entire home/apt', 'Hotel room', 'Shared room', 'sub_regions']]
def prepare_reg_annotation_lists():
"""
Creates the annotation in the form of groups within the data. Displays this on the right hand side of the heatmap.
"""
reg_sorted_list = location_rating.sub_regions.unique()
reg_len = location_rating.sub_regions.value_counts().to_dict()
sorted_len = []
cum_len = []
arrow_style_str_list = []
# here we define the width of the bracket used, which is proportional to the number of boroughs within a sub region
for i in range(5):
if i==0:
value = reg_len[reg_sorted_list[i]]
cum_value = value
else:
value = reg_len[reg_sorted_list[i]]
cum_value += value
sorted_len.append(value)
cum_len.append(cum_value)
arrow_style_str_list.append('-[,widthB='+str((value/1.2)-0.5)+',lengthB=0.7')
# here we define ticks which represent the center location of each sub region relative to the heatmap
Ticks = []
for i in range(5):
if i == 0:
Ticks.append(1-((cum_len[i]/2)/33))
else:
Ticks.append(1-((((cum_len[i]-cum_len[i-1])/2)+cum_len[i-1])/33))
return Ticks,arrow_style_str_list,reg_sorted_list
location_rating = location_rating.replace(np.nan, 2.5)
location_rating = add_regions(location_rating, 'neighbourhood')
location_rating = sort_data(location_rating)
Ticks_h,arrow,region = prepare_reg_annotation_lists()
A diverging red-green palate is chosen to represent good reviews and bad reviews.
red_green_cmap = sns.diverging_palette(10, 133,as_cmap=True)
red_green_cmap

fig, ax = plt.subplots(figsize=[20,len(location_rating)/3.3])
sns.heatmap(data=location_rating[['Private room', 'Entire home/apt', 'Hotel room', 'Shared room']],
annot=False, cbar_kws={"shrink":0.5,"orientation":'vertical'},linewidths=0.004,linecolor='grey',vmin=2.25,vmax=4.75,
cmap = red_green_cmap)
plt.title("Average ratings for different locations in London", fontsize=20, y=1.1,loc='left')
plt.text(0,-1,'Heatmap depicting the ratings among different locations in London. If no rating is available, minimum rating of 2.5 is assumed. \n Good ratings are ratings above 3.5 while bad ratings are below. The data is grouped by location (right) and sorted by average rating.',ha='left', fontsize=12)
ax.set_ylabel('')
#annotation for the borough
for i in range(5):
ax.annotate(region[i],xy=(1.01,Ticks_h[i]), xytext=(1.02,Ticks_h[i]), xycoords='axes fraction',
ha='left',va='center', arrowprops=dict(arrowstyle=arrow[i],lw=1))
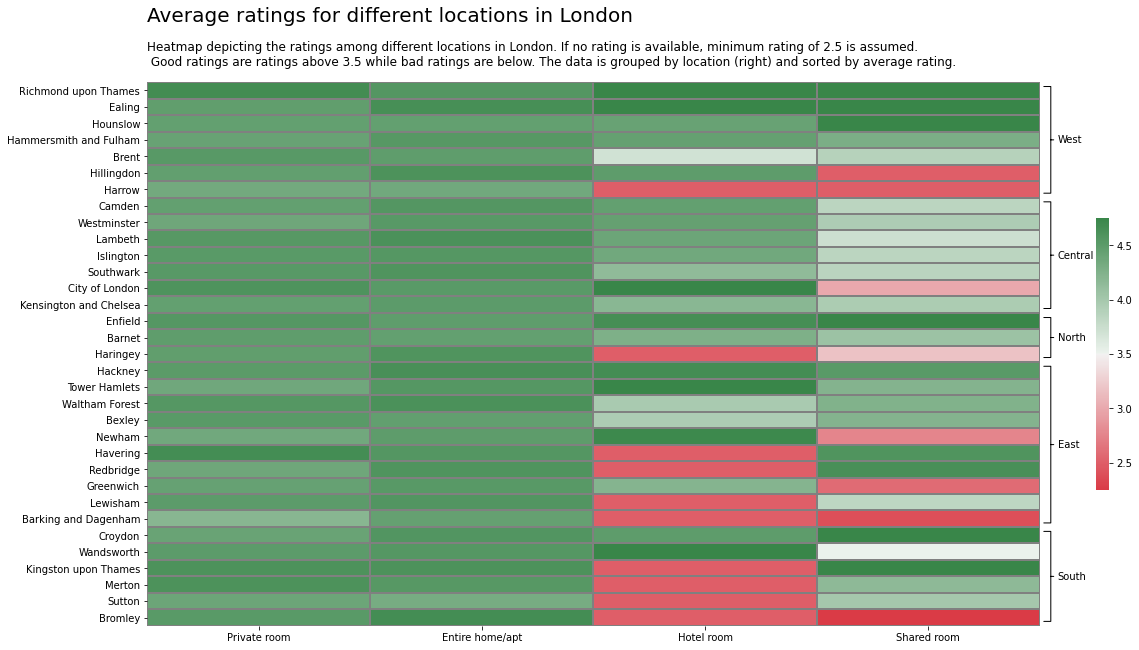
We can see the ratings are good across the private rooms and entire home. The best location in each zone is:
- West: Richmond upon Thames
- Central: Camden
- North: Enfield
- East: Hackney
- South: Croydon
Treemap¶
In this context, it's not fair to compare ratings of different locations as we have seen that their popularities are different. So there could be 10 reviews in one location while 100 reviews in another. To combine them, we can use a treemap.
reviews_treemap = listing_detailed.groupby(['neighbourhood_cleansed']).\
aggregate({'review_scores_rating':'mean', 'number_of_reviews':'sum'}).reset_index()
reviews_treemap = add_regions(reviews_treemap, 'neighbourhood_cleansed')
#change col names for nice viz on hover
reviews_treemap.columns = ['neighbourhood', 'Average Reviews', 'Number of reviews', 'regions']
fig = px.treemap(reviews_treemap, path=[px.Constant("London"), 'regions', 'neighbourhood'], values='Number of reviews',
color = 'Average Reviews', color_continuous_scale='RdBu')
fig.update_layout(margin = dict(t=50, l=25, r=25, b=25))
fig.update_layout(title_text='Airbnb London: Ratings overview')
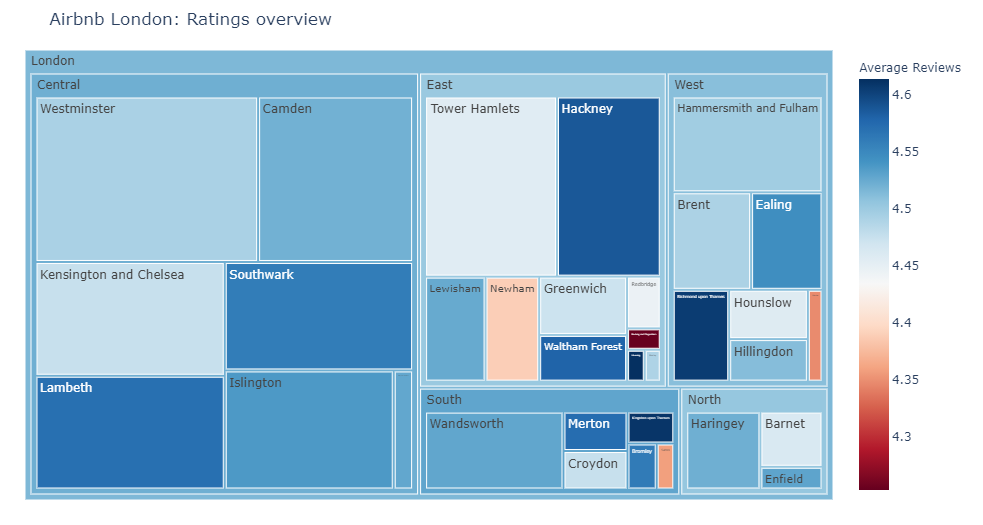
Word cloud¶
Now that we have classified the ratings into good ratings and bad ratings, let us look at the text in these ratings and identify if there are any patterns.
reviews_detailed_text = pd.merge(listing_detailed[['id', 'description','neighborhood_overview', 'host_about', 'review_scores_rating']], reviews, left_on = 'id', right_on = 'listing_id')
reviews_detailed_positive_text = reviews_detailed_text[reviews_detailed_text.review_scores_rating > 3.75]
reviews_detailed_negative_text = reviews_detailed_text[reviews_detailed_text.review_scores_rating <= 3.75]
Selecting 100 random reviews each for positive and negative sets.
pos_reviews_text = reviews_detailed_positive_text.sample(n=100, random_state = 2).comments.str.cat()
neg_reviews_text = reviews_detailed_negative_text.sample(n=100, random_state = 3).comments.str.cat()
Word cloud for positive reviews
# !pip install wordcloud
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from PIL import Image
mask_pos = np.array(Image.open('thumbs-up-xxl.png'))
# word cloud, good vs bad ratings
stop_words = ["https", "co", "RT", 'br', '<br>', '<br/>', '\r', 'r'] + list(STOPWORDS)
wordcloud_pattern = WordCloud(stopwords = stop_words, background_color="white", max_words=2000, max_font_size=256,
random_state=42, mask = mask_pos, width=mask_pos.shape[1], height=mask_pos.shape[0])
wordcloud_positive = wordcloud_pattern.generate(pos_reviews_text)
plt.imshow(wordcloud_positive, interpolation='bilinear')
plt.axis("off")
plt.show()

Word cloud for negative reviews
mask_neg = np.array(Image.open('thumbs-down-xxl.png'))
# word cloud, good vs bad ratings
wordcloud_pattern = WordCloud(stopwords = stop_words, background_color="white", max_words=2000, max_font_size=256,
random_state=42, mask = mask_neg, width=mask_neg.shape[1], height=mask_neg.shape[0])
wordcloud_neg = wordcloud_pattern.generate(neg_reviews_text)
plt.imshow(wordcloud_neg, interpolation='bilinear')
plt.axis("off")
plt.show()

Combining the positive and negative reviews in one plot to compare the differences:
fs, axs = plt.subplots(1, 2, figsize=(20,10))
plt.suptitle("Airbnb London: Wordcloud of positive and negative reviews", fontsize=20)
plt.figtext(0.5, 0.925, 'Wordcloud derived from a random sample of 100 positive and 100 negative reviews.',
wrap=True, horizontalalignment='center', fontsize=12)
axs[0].imshow(wordcloud_positive, interpolation='bilinear')
axs[0].axis("off")
axs[1].imshow(wordcloud_neg, interpolation='bilinear')
axs[1].axis("off")
plt.show()

From these plots, we can see that automated postings, cancellations by hosts, and issues during arrival are the main issues that Airbnb should look into.
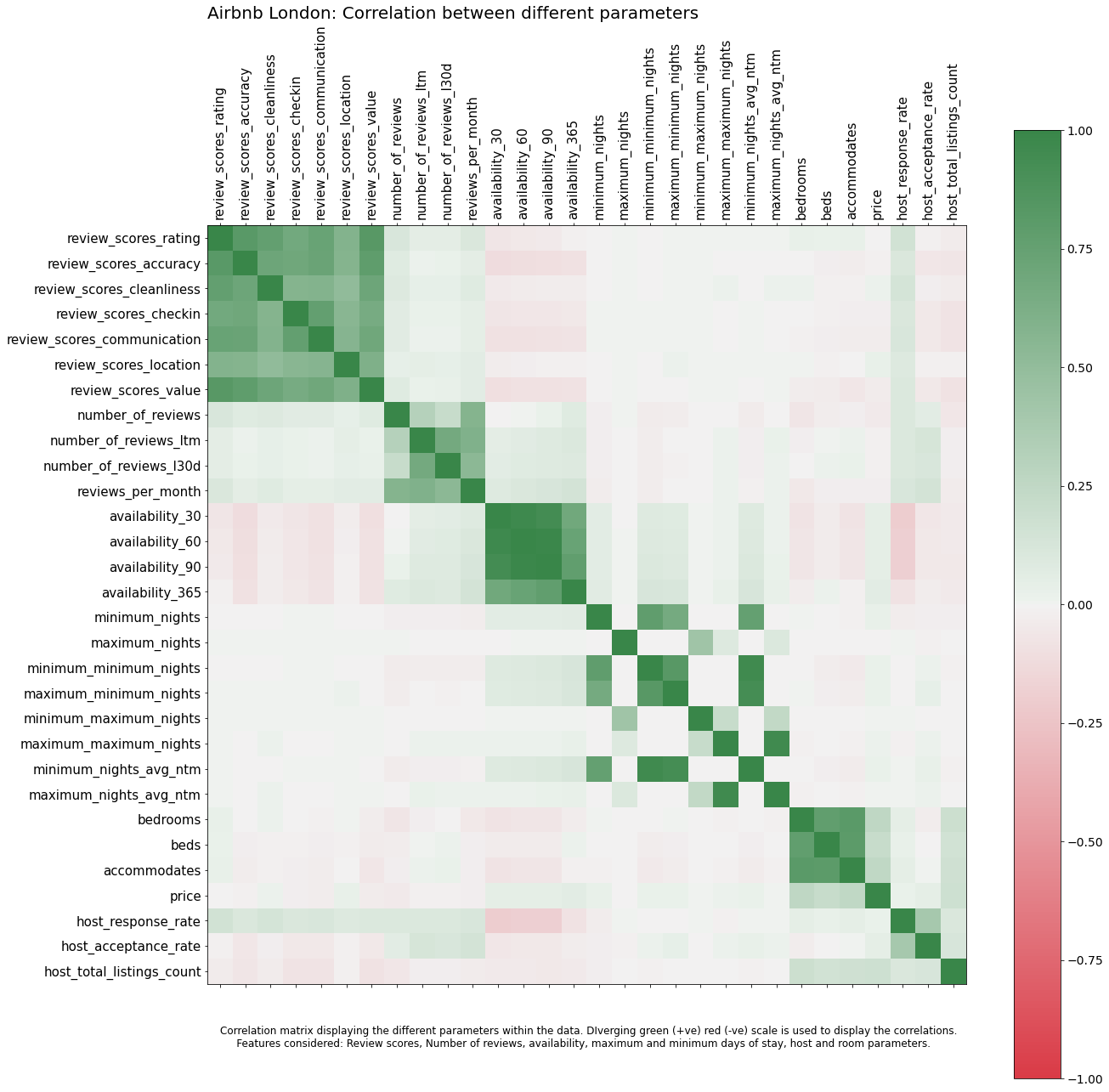
Correlation matrix¶
How are different parameters within the data related. How is ratings correlated with availability or maximum nights? This can be explained using a correlation plot.
listing_detailed['host_response_rate'] = listing_detailed['host_response_rate'].str.replace('%', '').astype(float)
listing_detailed['host_acceptance_rate'] = listing_detailed['host_acceptance_rate'].str.replace('%', '').astype(float)
listing_detailed['price'] = listing_detailed['price'].str.replace('$', '').str.replace(',', '').astype(float)
col_for_corr = ['review_scores_rating', 'review_scores_accuracy', 'review_scores_cleanliness', 'review_scores_checkin', 'review_scores_communication', 'review_scores_location', 'review_scores_value',
'number_of_reviews', 'number_of_reviews_ltm', 'number_of_reviews_l30d', 'reviews_per_month',
'availability_30', 'availability_60', 'availability_90', 'availability_365',
'minimum_nights', 'maximum_nights', 'minimum_minimum_nights', 'maximum_minimum_nights', 'minimum_maximum_nights', 'maximum_maximum_nights', 'minimum_nights_avg_ntm', 'maximum_nights_avg_ntm',
'bedrooms', 'beds','accommodates', 'price',
'host_response_rate', 'host_acceptance_rate', 'host_total_listings_count']
f = plt.figure(figsize=(20, 20))
plt.matshow(listing_detailed[col_for_corr].corr(), fignum = f, cmap = red_green_cmap, vmin=-1, vmax=1)
plt.xticks(range(listing_detailed[col_for_corr].select_dtypes(['number']).shape[1]),
listing_detailed[col_for_corr].select_dtypes(['number']).columns, rotation=90, fontsize = 15)
plt.yticks(range(listing_detailed[col_for_corr].select_dtypes(['number']).shape[1]),
listing_detailed[col_for_corr].select_dtypes(['number']).columns, rotation=0, fontsize = 15)
cb = plt.colorbar()
cb.ax.tick_params(labelsize=14)
plt.title("Airbnb London: Correlation between different parameters", fontsize=20,loc='left')
plt.text(0,32,'Correlation matrix displaying the different parameters within the data. DIverging green (+ve) red (-ve) scale is used to display the correlations.\n \
Features considered: Review scores, Number of reviews, availability, maximum and minimum days of stay, host and room parameters.',
ha='left', fontsize=12)
plt.show()
Scatterplot matrix¶
While the above plot shows the correlation across various variables, I want to deep dive into change in ratings with price. I can use a scatterplot matrix to visualise this. Additionally, I want the costliest properties, and the most popular yet cheap properties annotated.
def annotate_plot(x, y, **kwargs):
if(x.name == 'price' and y.name == 'review_scores_rating'):
ax = plt.gca()
for index, obj in listing_detailed.nlargest(2, 'price').iterrows():
plt.annotate(
obj['name'], # the text
xy=(obj.price, obj.review_scores_rating),
xytext=(7500, obj.review_scores_rating-0.5),
arrowprops=dict(arrowstyle="->")
)
elif(x.name == 'price' and y.name == 'number_of_reviews'):
ax = plt.gca()
for index, obj in listing_detailed.nlargest(3, 'number_of_reviews').iterrows():
ax.text(obj.price, obj.number_of_reviews, obj['name'])
col_for_pairplot = ['review_scores_rating', 'number_of_reviews', 'price']
sns_plot = sns.pairplot(listing_detailed, vars = col_for_pairplot, kind='scatter', hue = 'room_type', diag_kind='kde',)
sns_plot.fig.set_size_inches(20, 20)
sns_plot._legend.set_bbox_to_anchor((0.15, 0.89))
sns_plot.map_upper(annotate_plot)
sns_plot.fig.suptitle("Airbnb London: Scatterplot matrix", fontsize = 20, y=1)
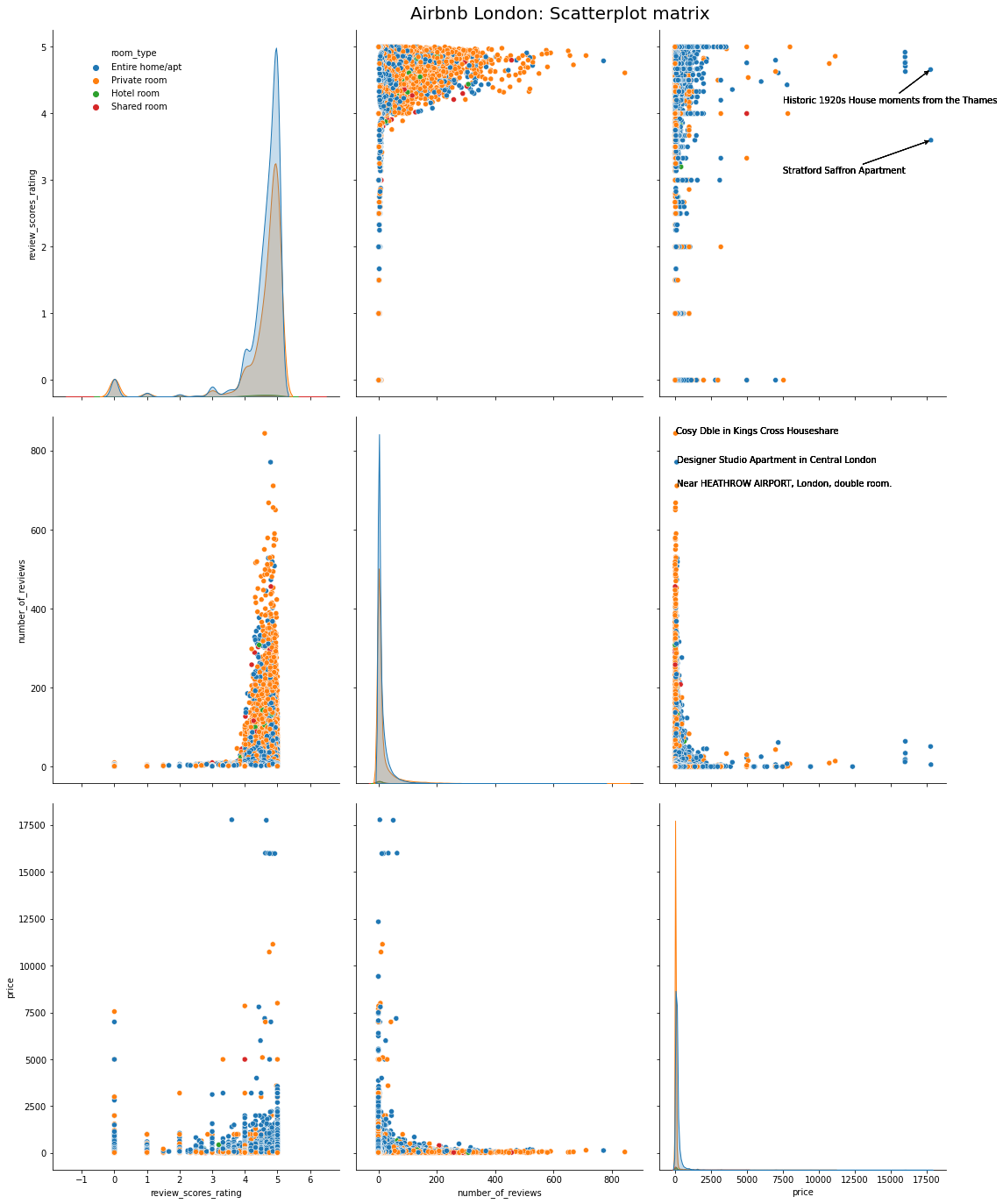
We can see that the two costliest properties are either historic apartments or a mansion. The three most popular yet cheap properties are small and quaint properties near popular destinations.
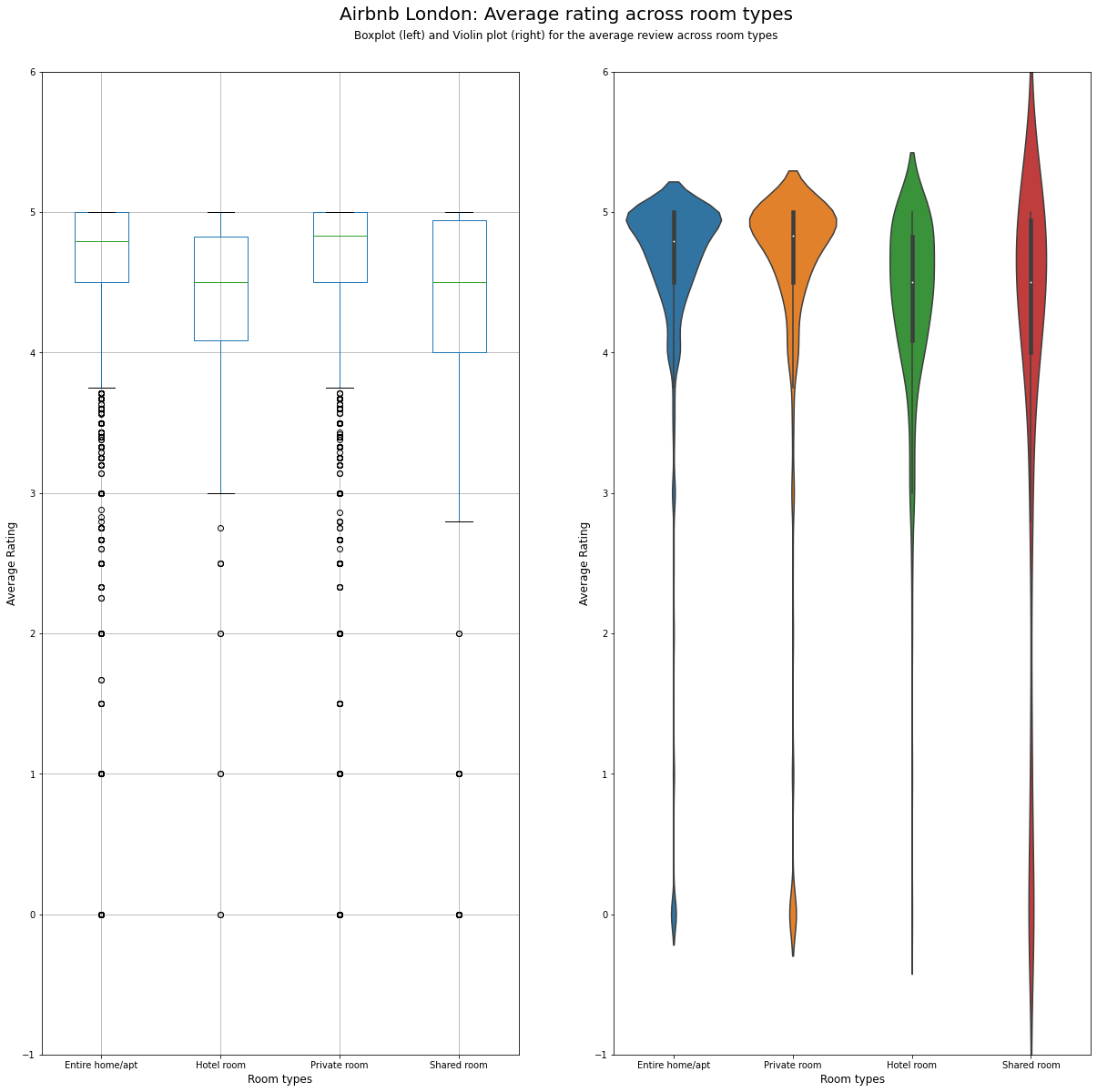
Boxplot and Violin chart¶
To look at the variation in ratings within the different room types, we could use either a boxplot or a Violin plot as shown.
fs, axs = plt.subplots(1, 2, figsize=(20,20))
listing_detailed.boxplot(column = 'review_scores_rating', by = 'room_type', figsize = (10,20), ax = axs[0])
sns.violinplot('room_type','review_scores_rating', data=listing_detailed, ax = axs[1])
plt.suptitle("Airbnb London: Average rating across room types", fontsize = 20, y=0.95)
plt.figtext(0.5, 0.925, 'Boxplot (left) and Violin plot (right) for the average review across room types',
wrap=True, horizontalalignment='center', fontsize=12)
axs[0].set_title('')
for ax in axs:
ax.set_ylim(-1, 6)
ax.set_ylabel('Average Rating', fontsize=12)
ax.set_xlabel('Room types', fontsize=12)
Cluster map¶
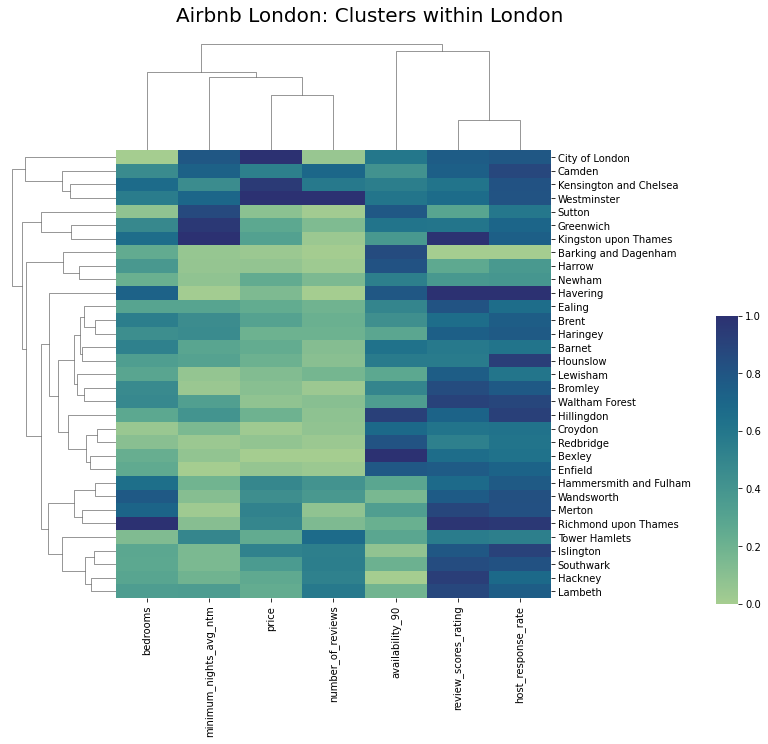
If we wanted to cluster localities based on some features, then cluster map is the ideal choice. In the below map, we cluster different locations based on one feature from each type. The features are also clustered to show the similarity between features. Finally, we use a white-blue colour palette for displaying the variation within the data.
from sklearn.preprocessing import MinMaxScaler
import seaborn as sns
col_for_corr = [ 'price', 'review_scores_rating', 'number_of_reviews', 'availability_90', 'minimum_nights_avg_ntm', 'bedrooms',
'host_response_rate']
df_cluster = listing_detailed.groupby('neighbourhood_cleansed').aggregate({
'review_scores_rating':'mean',
'number_of_reviews':'sum',
'availability_90':'mean',
'minimum_nights_avg_ntm':'mean',
'bedrooms':'mean',
'price':'mean',
'host_response_rate':'mean'
}).reset_index()
scaler = MinMaxScaler()
df_cluster1 = pd.DataFrame(scaler.fit_transform(df_cluster[col_for_corr]), columns=col_for_corr)
df_cluster1.index = df_cluster.neighbourhood_cleansed
crest_cmap = sns.color_palette("crest", as_cmap=True)
crest_cmap

g = sns.clustermap(df_cluster1, cmap = crest_cmap, vmin = 0, vmax = 1)
plt.title("Airbnb London: Clusters within London", fontsize=20,loc='left', y = 2, x = -25)
g.ax_cbar.set_position((1, .2, .03, .4))
g.ax_heatmap.set_ylabel("")
plt.show()
References¶
- Visualisation Analytics and Design, Tamara Munzner
- Class notes and assignments, Visualisation module, MSc Business Analytics, Imperial College London, Class 2020-22
- Ahmed Khedr, Ankit Mahajan, Harsha Achyuthuni, Shaked Atia Report: Visualizing demand,supply,prices and ratings for Airbnb in London
- Visual Analytics lab at JKU Linz