Handling databases using python¶
I want to store predictions and actual values for air pollution near my home in Hyderabad. In an earlier blog I deployed a flask application that predicts PM2.5. This post shows how to persist those predictions and historic values in Neon Postgres so they are available for visualization and analytics later.
Free database on NeonDB¶
Neon is serverless Postgres which separates compute and storage, provides autoscaling (e.g., 0.25→2 CU), branching for dev/prod workflows, and managed TLS for free. This means we dont need to size servers, just connect, and we can build small scale projects for free.
Setting up¶
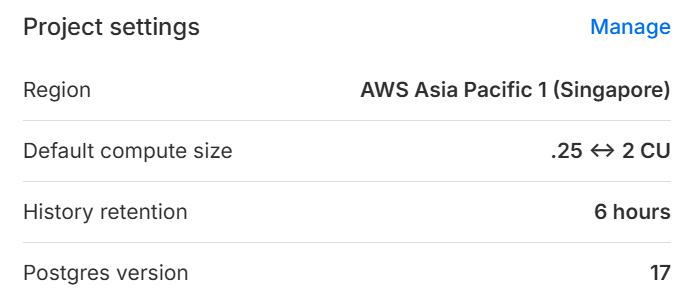
- In the Neon Console, create a new project.
- Keep region as AWS Asia Pacific 1 (Singapore) (Or whichever is suitable), Postgres 17, and default autoscaling 0.25 ↔ 2 CU.
- A database (neondb) and a production branch will be created. Optionally create a development branch off production for testing.
2) Connection strings & security: Copy the connection string from the Connect button in the console. postgresql://: @ .ap-southeast-1.aws.neon.tech/ ?sslmode=require&channel_binding=require
Creating tables¶
Once we have a cluster created, we can create tables in three ways.
1. Using SQL commands on "SQL Browser"
2. Using psycopg2 in Python
3. Using SQLAlchemy
We have to create two tables
1. daily_historic_pollution(date PRIMARY KEY, type, value)
2. daily_prediction_pollution(date PRIMARY KEY, type, prediction)
SQL Queries¶
First, let us create a table using SQL Browser. For creating a new table "daily_historic_pollution" which will contain the historic pollution data of Hyderabad we can use the following query.
CREATE DATABASE hyderabad_aqi;
CREATE TABLE daily_historic_pollution(
date DATE PRIMARY KEY,
type VARCHAR(20),
value FLOAT
);
Load data using python¶
We can use psycopg to connect and create the same table. The URL to connect is provided by ElephantSQL under "Details".
After connecting to the database, we can create tables using SQL commands.
import psycopg2
connection_string = "postgresql://username:password@hostname:hostnumber/database"
conn = psycopg2.connect(connection_string)
conn.set_session(autocommit=True)
cur = conn.cursor()
cur.execute(
"""
DROP TABLE IF EXISTS daily_historic_pollution
""")
cur.execute(
"""
CREATE TABLE daily_historic_pollution (date DATE PRIMARY KEY,
type VARCHAR(20),
value INTEGER
)
""")
print("Created table")
cur.close()
conn.close()
Created table
SqlAlchemy¶
According to me, the best way to interface with a database is using SqlAlchemy. For example, consider the data from AQICN's API on the air pollution data for Hyderabad.
import pandas as pd
df = pd.read_csv('hyderabad-us consulate, india-air-quality.csv')
df['type'] = 'pm25'
df.columns = ['date', 'value', 'type']
df.head()
| date | value | type | |
|---|---|---|---|
| 0 | 2021/10/1 | 87 | pm25 |
| 1 | 2021/10/2 | 47 | pm25 |
| 2 | 2021/10/3 | 50 | pm25 |
| 3 | 2021/9/1 | 66 | pm25 |
| 4 | 2021/9/2 | 74 | pm25 |
Using SqlAlchemy, we can upload this data to the previously created table.
from sqlalchemy import create_engine
import numpy
from psycopg2.extensions import register_adapter, AsIs
def addapt_numpy_float64(numpy_float64):
return AsIs(numpy_float64)
def addapt_numpy_int64(numpy_int64):
return AsIs(numpy_int64)
register_adapter(numpy.float64, addapt_numpy_float64)
register_adapter(numpy.int64, addapt_numpy_int64)
engine = create_engine(connection_string)
for i in range(len(df)):
query = """INSERT INTO daily_historic_pollution (date, type, value) VALUES(%s, %s, %s)
ON CONFLICT (date) DO UPDATE
SET type = excluded.type,
value = excluded.value;
"""
engine.execute(query, (df.date[i], df.type[i], df.value[i]))
HTTP requests¶
In this way, we can load data into a database. Now I want to create a new table that can store the predictions from the flask application into a table.
conn = psycopg2.connect(connection_string)
conn.set_session(autocommit=True)
cur = conn.cursor()
cur.execute(
"""
DROP TABLE IF EXISTS daily_prediction_pollution
""")
cur.execute(
"""
CREATE TABLE daily_prediction_pollution (date DATE PRIMARY KEY,
type VARCHAR(20),
prediction FLOAT
)
""")
print("Created table")
cur.close()
conn.close()
Created table
We can use the GET request from the flask application in the previous blog to predict PM25 for the date.
import requests
from datetime import date, datetime
today = str(date.today().year)+'-'+str(date.today().month)+'-'+str(date.today().day)
response = requests.get("https://harshaash.pythonanywhere.com/predict", params={'date': today})
response.json()['prediction'][0]
115.6
The prediction is 115.6 PM25. We can use our knowledge on SqlAlchemy to store this value in a database.
query2 = """INSERT INTO daily_prediction_pollution (date, type, prediction) VALUES(%s, %s, %s)
ON CONFLICT (date) DO UPDATE
SET type = excluded.type,
prediction = excluded.prediction;
"""
engine.execute(query2, (today, 'pm25', response.json()['prediction'][0]))
We can see this result in the database 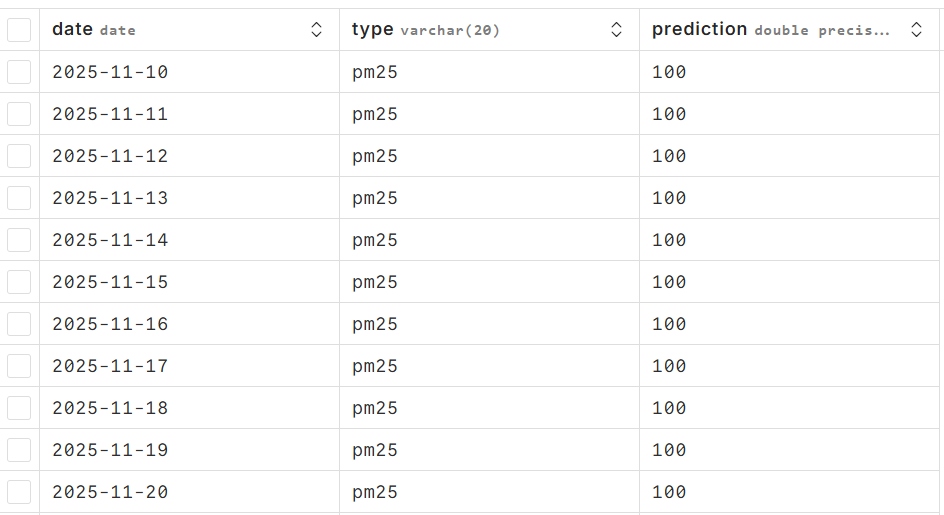 We can get actual pollution data for the past from JSON API of AQICN.org. We can use this data to update the database with the previous day's value.
We can get actual pollution data for the past from JSON API of AQICN.org. We can use this data to update the database with the previous day's value.
aqi_token = {'token':'default_token'}
response = requests.get("https://api.waqi.info/feed/hyderabad/", params=aqi_token)
data = pd.DataFrame(response.json()['data']['forecast']['daily']['pm25'])
data.day = pd.to_datetime(data.day)
data['type'] = 'pm25'
data.columns = ['value', 'date', 'max', 'min', 'type']
data
| value | date | max | min | type | |
|---|---|---|---|---|---|
| 0 | 158 | 2021-10-15 | 159 | 145 | pm25 |
| 1 | 150 | 2021-10-16 | 159 | 138 | pm25 |
| 2 | 152 | 2021-10-17 | 169 | 138 | pm25 |
| 3 | 140 | 2021-10-18 | 159 | 138 | pm25 |
| 4 | 145 | 2021-10-19 | 158 | 138 | pm25 |
| 5 | 138 | 2021-10-20 | 138 | 138 | pm25 |
| 6 | 134 | 2021-10-21 | 138 | 89 | pm25 |
| 7 | 133 | 2021-10-22 | 138 | 89 | pm25 |
| 8 | 138 | 2021-10-23 | 138 | 138 | pm25 |
From the API result, we can see the previous two day's data and predictions (by AQICN) for the next few days. We can use this API to update the data for previous day's data in our table.
for i in range(2):
query = """INSERT INTO daily_historic_pollution (date, type, value) VALUES(%s, %s, %s)
ON CONFLICT (date) DO UPDATE
SET type = excluded.type,
value = excluded.value;
"""
engine.execute(query, (data.date[i], data.type[i], data.value[i]))
Scheduling using GitHub Actions¶
I want to run these predictions every day, and the data/predictions are stored at a set point of time every day. To do this, we can combine all the codes above into one python file that gets executed every day. This file contains code that will predict the pollution for today and store this value along with the pollution for yesterday in the database.
# File name: aqi_script.py
import pandas as pd
import requests
from datetime import date, datetime
from sqlalchemy import create_engine
import numpy
from psycopg2.extensions import register_adapter, AsIs
def addapt_numpy_float64(numpy_float64):
return AsIs(numpy_float64)
def addapt_numpy_int64(numpy_int64):
return AsIs(numpy_int64)
register_adapter(numpy.float64, addapt_numpy_float64)
register_adapter(numpy.int64, addapt_numpy_int64)
connection_string = "postgresql://username:password@hostname:hostnumber/database"
engine = create_engine(connection_string)
today = str(date.today().year)+'-'+str(date.today().month)+'-'+str(date.today().day)
# Upload the prediction data
response = requests.get("https://harshaash.pythonanywhere.com/predict", params={'date': today})
query2 = """INSERT INTO daily_prediction_pollution (date, type, prediction) VALUES(%s, %s, %s)
ON CONFLICT (date) DO UPDATE
SET type = excluded.type,
prediction = excluded.prediction;
"""
engine.execute(query2, (today, 'pm25', response.json()['prediction'][0]))
# Upload the actual data
aqi_token = {'token':'dummy_token'}
response = requests.get("https://api.waqi.info/feed/hyderabad/", params=aqi_token)
data = pd.DataFrame(response.json()['data']['forecast']['daily']['pm25'])
data.day = pd.to_datetime(data.day)
data['type'] = 'pm25'
data.columns = ['value', 'date', 'max', 'min', 'type']
for i in range(2):
query = """INSERT INTO daily_historic_pollution (date, type, value) VALUES(%s, %s, %s)
ON CONFLICT (date) DO UPDATE
SET type = excluded.type,
value = excluded.value;
"""
engine.execute(query, (data.date[i], data.type[i], data.value[i]))
We can schedule this code to run every day at a particular time so that our database is updated every day with the predictions. This can be done using cron jobs. One way to implement cron jobs is using GitHub actions. To create a cron job, a yml file should be created within the .github/workflows folder in the GitHub repository. This yml file is converted to actions, and this is shown on the actions page. For more details, refer here. The yml file for our use case would be:
# FIle name: any_name.yml
# location: .github/workflows
name: update_database_AQI_data
on:
schedule:
- cron: '5 1 * * *' # to run at 1:05 AM GMT everyday
jobs:
build:
name: Build project
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v2 # Downloads the current git repo
- name: Setup Python
uses: actions/setup-python@v2 # Installs the python setup
- name: Install dependancies # Installs the required packages
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Execute python file # Run the script file
run: python aqi_script.py
Created by Achyuthuni Sri Harsha