ML using scikit learn¶
Predicting absenteeism¶
A large problem within organisations is how to motivate their employees. This is a continuation of the previous blog where we went through various feature engineering methods to come up with a comprehensive dataset. In this blog, we will use this data in order to predict employment absenteeism. The goal is to identify who are likely to be absent in the near future. This blog doesn't go through the machine learning concepts, or business logic, but implementation of machine learning using scikit-learn package in python.
As a first step, let us load and look at the data.
import warnings
warnings.filterwarnings('ignore', category=FutureWarning)
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
%matplotlib inline
pd.set_option('display.max_columns', None)
df = pd.read_csv("data_after_feature_engg.csv")
df['date'] = pd.to_datetime(df.date)
df.head()
| Unnamed: 0 | employee | date | last_likes | last_dislikes | feedbackType | likes_till_date | dislikes_till_date | last_2_likes | last_2_dislikes | days_since_last_comment | last_vote | timezone | stillExists | no_of_days_since_first_vote | no_of_votes_till_date | perc_days_voted | avg_vote_till_date | avg_vote | last_2_votes_avg | prev_vote | days_since_last_vote | employee_joined_after_jun17 | countdown_to_last_day | reason | on_leave | no_leaves_till_date | previous_day_leave | last_2_days_leaves | weekday | month | week | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 23729 | 17r | 2018-05-29 | 0.0 | 0.0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 3.0 | Europe/Madrid | 1.0 | 1 | 1.0 | 1.0 | 3.0 | 2.121212 | 0.0 | 0.0 | 0 | 1.0 | 999 | NaN | 0.0 | 0.0 | 0.0 | 0.0 | Tuesday | May | 1 |
| 1 | 23730 | 17r | 2018-05-30 | 0.0 | 0.0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 3.0 | Europe/Madrid | 1.0 | 1 | 1.0 | 1.0 | 3.0 | 2.121212 | 0.0 | 0.0 | 0 | 1.0 | 999 | NaN | 0.0 | 0.0 | 0.0 | 0.0 | Wednesday | May | 2 |
| 2 | 23731 | 17r | 2018-05-31 | 0.0 | 0.0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 3.0 | Europe/Madrid | 1.0 | 2 | 1.0 | 1.0 | 3.0 | 2.121212 | 0.0 | 0.0 | 1 | 1.0 | 999 | NaN | 0.0 | 0.0 | 0.0 | 0.0 | Thursday | May | 3 |
| 3 | 23732 | 17r | 2018-06-01 | 0.0 | 0.0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 3.0 | Europe/Madrid | 1.0 | 3 | 2.0 | 0.5 | 3.0 | 2.121212 | 0.0 | 3.0 | 0 | 1.0 | 999 | NaN | 0.0 | 0.0 | 0.0 | 0.0 | Friday | Jun | 1 |
| 4 | 23733 | 17r | 2018-06-02 | 0.0 | 0.0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 3.0 | Europe/Madrid | 1.0 | 4 | 2.0 | 0.5 | 3.0 | 2.121212 | 0.0 | 0.0 | 0 | 1.0 | 999 | NaN | 0.0 | 0.0 | 0.0 | 0.0 | Saturday | Jun | 2 |
Base model¶
This data is at an employee-day level, and we can predict if any employee will take leave on any particular date. As very few employees take leave on any particular day, we will have a highly imbalanced dataset.
1-df.on_leave.mean()
0.9514513766404592
This indicates that only 5% of the dataset contains information about employees taking leaves. This means that if we predicted that all the employees are not taking a leave (class 0), we would be 95% accurate, but such prediction is not useful. This is the base model, and we need to see to it that we have accuracy greater than 95%.
Decision Tree Classifier¶
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score, KFold
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay, accuracy_score, roc_curve, roc_auc_score
From the different features that we have created, we are selecting what we think will be relevant features for predicting which employee might be absent.
indep_vars = ['last_likes', 'last_dislikes', 'feedbackType',
'likes_till_date', 'dislikes_till_date', 'last_2_likes', 'last_2_dislikes',
'days_since_last_comment', 'last_vote', 'timezone', 'stillExists',
'no_of_days_since_first_vote', 'no_of_votes_till_date',
'perc_days_voted', 'avg_vote_till_date', 'avg_vote', 'last_2_votes_avg',
'days_since_last_vote', 'employee_joined_after_jun17', 'countdown_to_last_day',
'no_leaves_till_date', 'weekday', 'month']
The dependent variable is on_leave. We are also creating dummy variables that represent categorical data.
data_targets = df['on_leave'].astype('int')
data_features = pd.get_dummies(df[indep_vars], prefix = "_", drop_first= True)
To prevent overfitting, we are splitting the data into test data and train data. Test data has 30% of the data (selected randomly) while the train data has the remaining 70% on which we train the model. This model is tested against the test data to validate for overfitting.
x_train, x_test, y_train, y_test = train_test_split(data_features, data_targets, test_size=.30, random_state=35, \
stratify=data_targets)
Before building an ensemble of models, we can build a decision tree model and understand if the features we have selected perform the classification reasonably.
tree_clf = DecisionTreeClassifier(random_state=35, max_depth=3, class_weight="balanced").fit(x_train,y_train)
def plot_feature_importance(model):
fs, ax = plt.subplots(1, figsize=(20,10))
number_of_features = x_train.shape[1]
plt.barh(range(number_of_features), model.feature_importances_, align='center')
plt.yticks(np.arange(number_of_features),x_train.columns)
plt.xlabel("Feature Importance")
plt.ylabel("Feature")
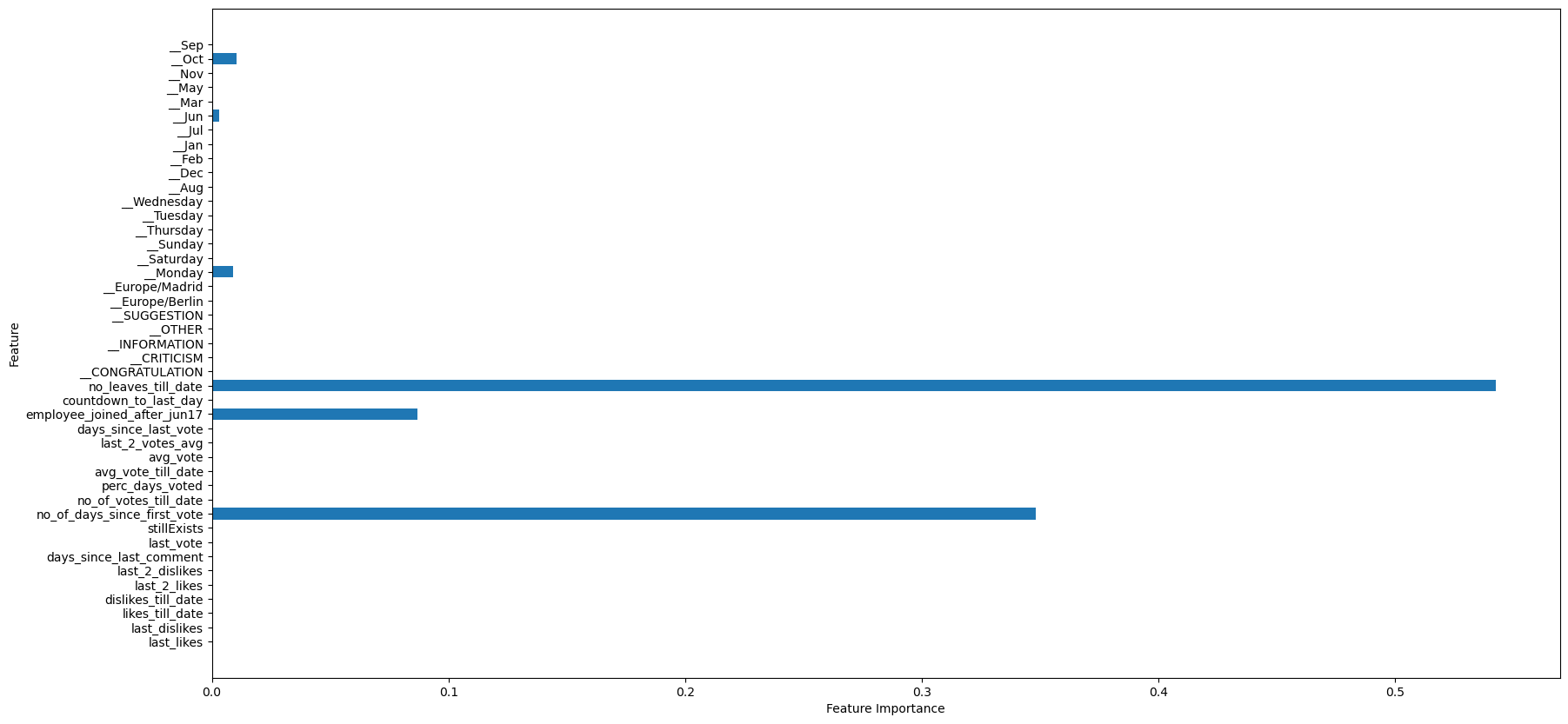
plot_feature_importance(tree_clf)
plt.figure(figsize=(20,20))
plot_tree(tree_clf, fontsize=10, feature_names = x_train.columns)
plt.show()
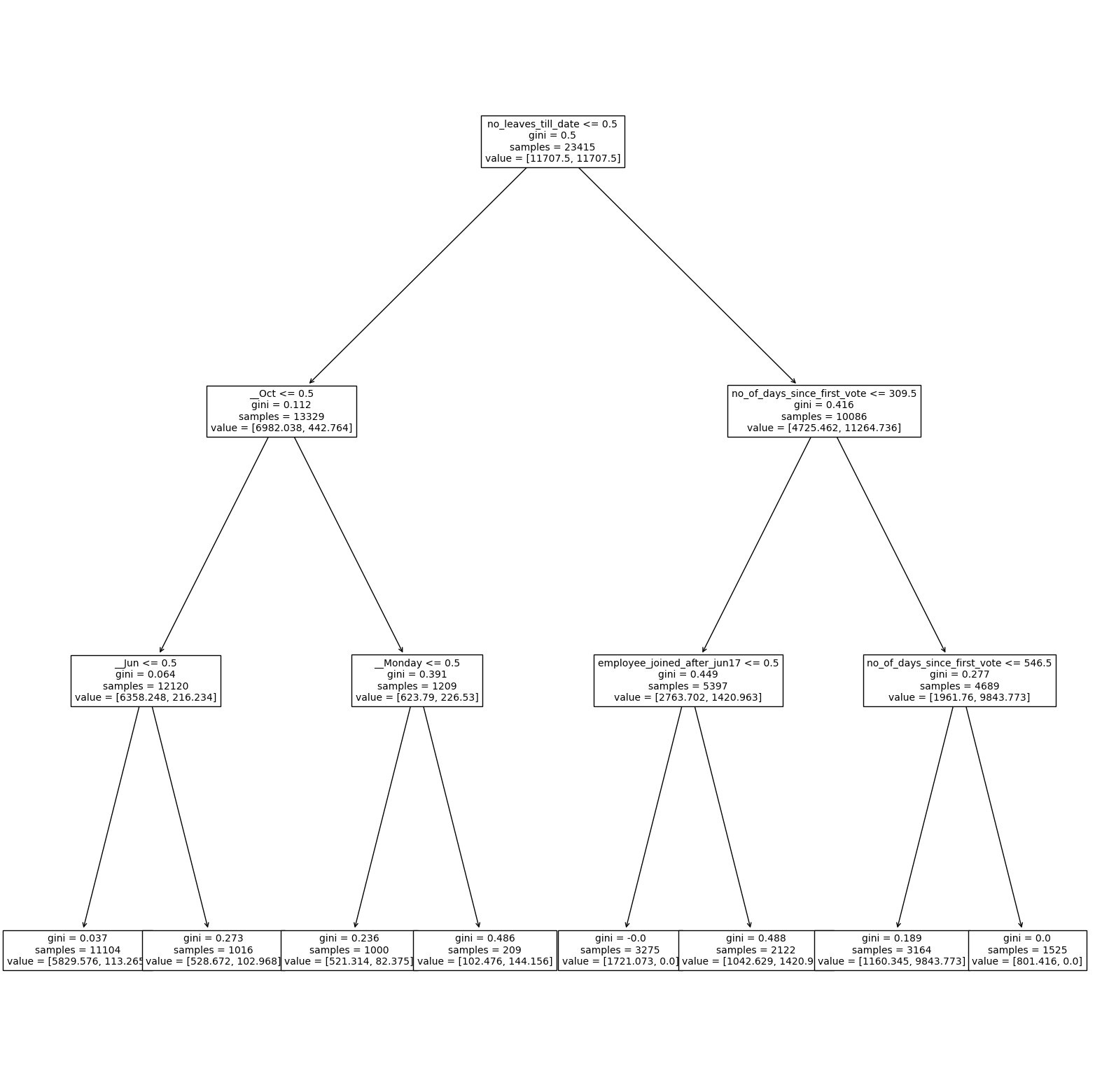
We can observe that the features that are important make reasonable sense. 1. Number of leaves till date: The number of leaves that an employee has taken already will affect the future leaves that a person would take 2. number of days since first vote (proxy to the employee tenure), employee_joined_after_Jun17 (proxy to newer employees) are significant, and we have seen these trends in the visualizations in the feature engineering section 3. As seen in the visualisations, employees took leaves during months like June and October which have come up as significant in the analysis
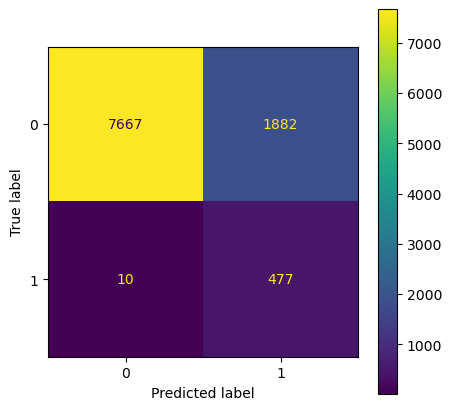
We can see the model is not overfit with similar accuracy across test and train datasets. The confusion matrix is plotted below:
def plot_confusion_matrix(model, x_test, y_test):
plt.rcParams["figure.figsize"] = (5, 5)
disp = ConfusionMatrixDisplay(confusion_matrix=confusion_matrix(y_test, model.predict(x_test), labels=model.classes_),
display_labels=model.classes_)
disp.plot()
plt.show();
print('Accuracy on train data is', round(tree_clf.score(x_train, y_train),2))
print('Accuracy on test data is', round(tree_clf.score(x_test, y_test),2))
plot_confusion_matrix(tree_clf, x_test, y_test)
Accuracy on train data is 0.81
Accuracy on test data is 0.81
y_test_pred = tree_clf.predict(x_test)
print(classification_report(y_test, y_test_pred))
precision recall f1-score support
0 1.00 0.80 0.89 9549
1 0.20 0.98 0.34 487
accuracy 0.81 10036
macro avg 0.60 0.89 0.61 10036
weighted avg 0.96 0.81 0.86 10036
We can observe that the precision is just 20% (on classifying when an employee will take a leave). This is due to imbalance of classes. This can be rectified by many ways, one of which includes under-sampling. For other methods, refer the blog on handling imbalanced classes. We are also using GridSearch to find the best tuning parameters and n-fold cross validation.
Downsampling¶
from imblearn.pipeline import Pipeline, make_pipeline
from imblearn.under_sampling import RandomUnderSampler
param_grid_dt = {
'classification__criterion': ['gini', 'entropy'],
'classification__max_depth': [2,5,10],
'classification__max_features':[0.2, 0.5, 0.8]
}
model_dt_p = Pipeline([
('sampling', RandomUnderSampler()), # While training, downsample the majority class randomly
('classification', DecisionTreeClassifier()) # Train and predict using rf classification model
])
model_dt = GridSearchCV(model_dt_p, param_grid_dt, cv=5)
model_dt.fit(x_train, y_train)
GridSearchCV(cv=5,
estimator=Pipeline(steps=[('sampling', RandomUnderSampler()),
('classification',
DecisionTreeClassifier())]),
param_grid={'classification__criterion': ['gini', 'entropy'],
'classification__max_depth': [2, 5, 10],
'classification__max_features': [0.2, 0.5, 0.8]})
y_test_pred = model_dt.predict(x_test)
print(classification_report(y_test, y_test_pred))
print('Accuracy on train data is', round(model_dt.score(x_train, y_train),2))
print('Accuracy on test data is', round(model_dt.score(x_test, y_test),2))
precision recall f1-score support
0 1.00 0.97 0.98 9549
1 0.63 0.97 0.76 487
accuracy 0.97 10036
macro avg 0.81 0.97 0.87 10036
weighted avg 0.98 0.97 0.97 10036
Accuracy on train data is 0.97
Accuracy on test data is 0.97
Here we observe that with a simple decision tree classifier, we already reach an accuracy above 95% (base accuracy) with good precision and recall values. This model is better than our base model. We could further improve it by using ensemble methods which we will look into later in the blog.
def print_stats(model):
print('Best params for the model', model.best_params_)
print('Best score on the cross validation data', round(model.best_score_, 2))
print('Accuracy on train data', round(model.score(x_train, y_train),2))
print('Accuracy on test data', round(model.score(x_test, y_test),2))
print_stats(model_dt)
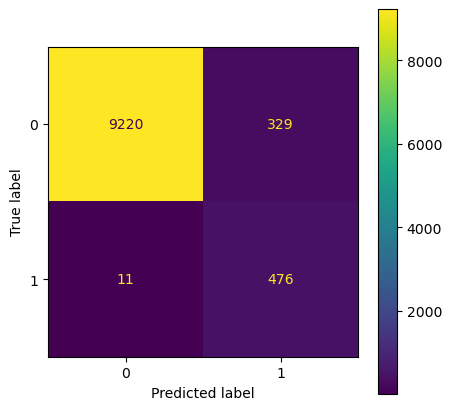
plot_confusion_matrix(model_dt, x_test, y_test)
Best params for the model {'classification__criterion': 'entropy', 'classification__max_depth': 10, 'classification__max_features': 0.5}
Best score on the cross validation data 0.96
Accuracy on train data 0.97
Accuracy on test data 0.97
y_test_pred = model_dt.predict(x_test)
print(classification_report(y_test, y_test_pred))
precision recall f1-score support
0 1.00 0.97 0.98 9549
1 0.63 0.97 0.76 487
accuracy 0.97 10036
macro avg 0.81 0.97 0.87 10036
weighted avg 0.98 0.97 0.97 10036
Multiple models¶
After manually applying a few models, we can scale up to use grid search method to search for the best classifier and parameters in a quick and efficient manner. We can use Logistic Regression, Multinomial Naive Bayes, KNN Classifiers, Ensemble models and any model in the sklearn library.
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier
from sklearn.pipeline import Pipeline
# setting up models
clf1 = LogisticRegression(random_state=35)
clf2 = MultinomialNB()
clf3 = KNeighborsClassifier()
clf4 = DecisionTreeClassifier(random_state=35)
clf5 = RandomForestClassifier(random_state = 35)
clf6 = GradientBoostingClassifier(random_state = 35)
# setting up hyperparameters
# Hyperparameters for Logistic regression https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
hyperparam1 = {}
hyperparam1['classifier__C'] = [10**-4, 10**-1, 10**0] # The hyper-parameter is C and its inside 'classifier' part of pipeline
hyperparam1['classifier__penalty'] = ['l1', 'l2'] # The hyper-parameter is penalty and its inside 'classifier' part of pipeline
hyperparam1['classifier__class_weight'] = [None, 'balanced']
hyperparam1['classifier'] = [clf1]
# Hyperparameters for Naive Bayes
hyperparam2 = {}
hyperparam2['classifier__alpha'] = [10**0,10**4]
hyperparam2['classifier'] = [clf2]
# Hyperparameters for KNN
hyperparam3 = {}
hyperparam3['classifier__n_neighbors'] = [2, 5, 10]
hyperparam3['classifier'] = [clf3]
# Hyperparameters for Decision Trees
hyperparam4 = {}
hyperparam4['classifier__max_depth'] = [2,5,10, None]
hyperparam4['classifier__min_samples_split'] = [2, 5, 10]
hyperparam4['classifier__class_weight'] = [None, 'balanced']
hyperparam4['classifier'] = [clf4]
# Hyperparameters for Random Forest
hyperparam5 = {}
hyperparam5['classifier__n_estimators'] = [100, 250]
hyperparam5['classifier__max_depth'] = [2,5,10]
hyperparam5['classifier__class_weight'] = [None, 'balanced']
hyperparam5['classifier'] = [clf5]
# Hyperparameters for Gradient Boosting
hyperparam6 = {}
hyperparam6['classifier__n_estimators'] = [100, 250]
hyperparam6['classifier__max_depth'] = [2, 5, 10]
hyperparam6['classifier__min_samples_split'] = [2, 5, 10]
hyperparam6['classifier'] = [clf6]
pipe = Pipeline([('classifier',clf1)])
hyperparam_total = [hyperparam1, hyperparam2, hyperparam3, hyperparam4, hyperparam5, hyperparam6]
%%time
# Record how long the search takes
# Train the grid search model
model_grid_search = GridSearchCV(pipe, hyperparam_total, cv=3, n_jobs=-1, scoring='roc_auc').fit(x_train, y_train)
CPU times: total: 48.2 s
Wall time: 3min 23s
# Output the best estimator which is a random forecast classifier
model_grid_search.best_estimator_
Pipeline(steps=[('classifier',
GradientBoostingClassifier(max_depth=5, min_samples_split=10,
n_estimators=250,
random_state=35))])
After running grid search to find the best parameters and models, we find the best model to be Gradient Boosting with the best parameters below.
# Output the parameters in the best estimator
model_grid_search.best_params_
{'classifier': GradientBoostingClassifier(random_state=35),
'classifier__max_depth': 5,
'classifier__min_samples_split': 10,
'classifier__n_estimators': 250}
The accuracy on the cross validated data close to 99%.
round(model_grid_search.best_score_, 4)
0.9981
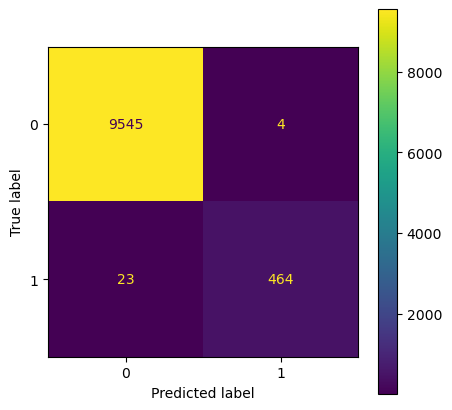
On the test data also, we have a near perfect precision, recall and accuracy.
y_test_pred = model_grid_search.predict(x_test)
print(classification_report(y_test, y_test_pred))
precision recall f1-score support
0 1.00 1.00 1.00 9549
1 0.99 0.95 0.97 487
accuracy 1.00 10036
macro avg 0.99 0.98 0.99 10036
weighted avg 1.00 1.00 1.00 10036
plot_confusion_matrix(model_grid_search, x_test, y_test)
plt.show();
The features that are used and their importances in the model is:
def print_most_imp_features(model, data_features):
feat_imp_df = pd.DataFrame({'columns' : data_features.columns, 'importance':(model.best_estimator_.named_steps["classifier"].feature_importances_*100).astype(int)})
return feat_imp_df[feat_imp_df.importance>0].sort_values('importance', ascending=False)
print_most_imp_features(model_grid_search, data_features)
| columns | importance | |
|---|---|---|
| 18 | no_leaves_till_date | 40 |
| 9 | no_of_days_since_first_vote | 22 |
| 32 | __Aug | 7 |
| 41 | __Oct | 6 |
| 37 | __Jun | 5 |
| 10 | no_of_votes_till_date | 2 |
| 12 | avg_vote_till_date | 2 |
| 13 | avg_vote | 2 |
| 2 | likes_till_date | 1 |
| 6 | days_since_last_comment | 1 |
| 11 | perc_days_voted | 1 |
| 21 | __INFORMATION | 1 |
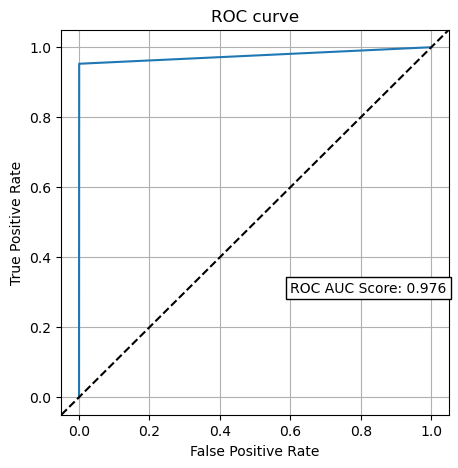
def plot_roc_curve(fpr, tpr, auc):
fig, ax = plt.subplots()
ax.plot(fpr, tpr)
ax.set(xlabel='False Positive Rate', ylabel='True Positive Rate')
ax.grid()
ax.text(0.6, 0.3, 'ROC AUC Score: {:.3f}'.format(auc),
bbox=dict(boxstyle='square,pad=0.3', fc='white', ec='k'))
lims = [np.min([ax.get_xlim(), ax.get_ylim()]), np.max([ax.get_xlim(), ax.get_ylim()])]
ax.plot(lims, lims, 'k--')
ax.set_xlim(lims)
ax.set_ylim(lims)
plt.title('ROC curve')
auc = roc_auc_score(y_test, y_test_pred)
fpr, tpr, _ = roc_curve(y_test, y_test_pred)
plot_roc_curve(fpr, tpr, auc)
Hyperopt¶
The Grid search works by trying every possible combination of parameters you want to try in your model, this means it will take a lot of time to perform the entire search which can get very computationally expensive. Hyperopt uses a form of Bayesian optimization for parameter tuning that allows you to get the best parameters for a given model. It can optimize a model with hundreds of parameters on a large scale.
from hyperopt import tpe, hp, fmin, STATUS_OK, space_eval, Trials
def get_best_hyperparameters(x_train, y_train, kfold=5):
def objective(params):
kfold = KFold(n_splits=3)
classification_type = params['type']
del params['type']
if classification_type == 'rf':
clf = RandomForestClassifier(**params)
elif classification_type == 'linreg':
clf = Ridge(**params)
elif classification_type == 'xgboost':
clf = GradientBoostingClassifier(**params)
elif classification_type == 'neural_network':
clf = MLPClassifier(**params)
elif classification_type == 'decision_tree':
clf = DecisionTreeClassifier(**params)
elif classification_type == 'lasso':
clf = Lasso(**params)
else:
return 0
score = cross_val_score(estimator=clf,
X=x_train, y=y_train, cv=kfold,
scoring='accuracy'
).mean()
return {'loss': -score, 'status': STATUS_OK}
search_space = hp.choice('classification_type', [
{
'type': 'rf',
"n_estimators": hp.choice("n_estimators_rf", [20, 50, 100, 150]),
"max_depth": hp.choice('max_depth_rf', range(3,30,1)),
"max_features": hp.choice("max_features_rf", ['sqrt', 'log2']),
"min_samples_split": hp.choice("min_samples_split_rf", [2,5,10]),
"min_samples_leaf": hp.choice("min_samples_leaf_rf", [1, 2, 4, 10]),
"bootstrap": hp.choice("bootstrap", [True, False]),
'class_weight':hp.choice('class_weight_rf', ['balanced', None]),
},
{
'type': 'xgboost',
'learning_rate': hp.choice('learning_rate_xgb', [0.0001,0.001, 0.01, 0.1, 1]),
'n_estimators' : hp.choice('n_estimators_xgb', range(100, 1000, 100)),
'max_depth' : hp.choice('max_depth_xgb', range(3,10,3)),
'min_weight_fraction_leaf' : hp.choice('min_weight_fraction_leaf_xgb', [i/20.0 for i in range(3,10)])
},
{
'type': 'logreg',
'penalty' : hp.choice('penalty_lr', ['l1', 'l2', 'elasticnet', None]),
'class_weight':hp.choice('class_weight_lr', ['balanced', None]),
'C':hp.choice('C_lr', [10**-4, 10**-1, 10**0])
},
{
'type': 'decision_tree',
"max_depth": hp.choice('max_depth_dt', range(3,10,3)),
"min_samples_split": hp.choice("min_samples_split_dt", [2,5,10]),
"min_samples_leaf": hp.choice("min_samples_leaf_dt", [4, 10]),
'class_weight':hp.choice('class_weight_dt', ['balanced', None]),
},
])
trials = Trials()
best_result = fmin(fn=objective, space=search_space, algo=tpe.suggest, max_evals=32, trials=trials)
# Print the values of the best parameters
print(space_eval(search_space, best_result))
return space_eval(search_space, best_result)
def create_model(best_hyperparameter):
if(best_hyperparameter['type'] == 'rf'):
return RandomForestClassifier(
bootstrap = best_hyperparameter['bootstrap'],
max_depth=int(best_hyperparameter['max_depth']),
max_features = best_hyperparameter['max_features'],
min_samples_leaf = int(best_hyperparameter['min_samples_leaf']),
min_samples_split=int(best_hyperparameter['min_samples_split']),
n_estimators = int(best_hyperparameter['n_estimators']),
class_weight = best_hyperparameter['class_weight']
)
elif(best_hyperparameter['type'] == 'xgboost'):
return GradientBoostingClassifier(
learning_rate=best_hyperparameter['learning_rate'],
n_estimators=int(best_hyperparameter['n_estimators']),
max_depth=int(best_hyperparameter['max_depth']),
min_weight_fraction_leaf=best_hyperparameter['min_weight_fraction_leaf']
)
elif(best_hyperparameter['type'] == 'logreg'):
return LogisticRegression(
penalty = best_hyperparameter['penalty'],
class_weight = best_hyperparameter['class_weight'],
C = best_hyperparameter['C']
)
elif(best_hyperparameter['type'] == 'decision_tree'):
return DecisionTreeClassifier(
max_depth=int(best_hyperparameter['max_depth']),
min_samples_leaf = int(best_hyperparameter['min_samples_leaf']),
min_samples_split=int(best_hyperparameter['min_samples_split']),
class_weight = best_hyperparameter['class_weight'],
)
best_hyperparameter = get_best_hyperparameters(x_train, y_train)
hyperopt_model = create_model(best_hyperparameter)
hyperopt_model.fit(x_train, y_train)
100%|███████████████████████████████████████████████| 32/32 [05:34<00:00, 10.46s/trial, best loss: -0.9956011103993166]
{'bootstrap': False, 'class_weight': None, 'max_depth': 28, 'max_features': 'log2', 'min_samples_leaf': 1, 'min_samples_split': 5, 'n_estimators': 100, 'type': 'rf'}
y_test_pred = hyperopt_model.predict(x_test)
print(classification_report(y_test, y_test_pred))
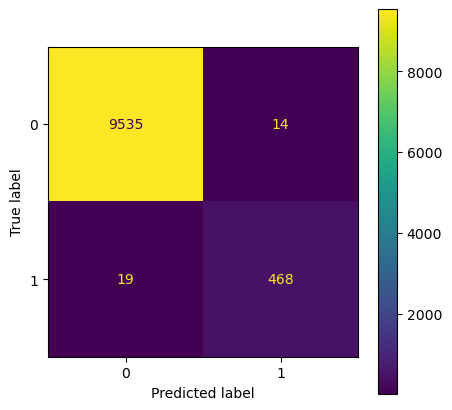
plot_confusion_matrix(hyperopt_model, x_test, y_test)
precision recall f1-score support
0 1.00 1.00 1.00 9549
1 0.99 0.96 0.98 487
accuracy 1.00 10036
macro avg 1.00 0.98 0.99 10036
weighted avg 1.00 1.00 1.00 10036
Predictions¶
Using this model, we can predict who is going to be absent in the next few days.
next_day_df = df[df.date == max(df.date)].reset_index()
next_day_df.no_of_days_since_first_vote += 1
next_day_df.days_since_last_vote += 1
day_name= ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday','Sunday']
month_name = [None, 'Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
next_day_df.date = next_day_df.date + pd.DateOffset(1)
next_day_df['weekday'] = next_day_df.date.dt.weekday.apply(lambda x:day_name[x])
next_day_df['month'] = next_day_df.date.dt.month.apply(lambda x:month_name[x])
next_day_df['week'] = next_day_df.date.dt.day
# Handle catogorical variables
next_day_df_predict = pd.get_dummies(next_day_df[indep_vars], prefix = "_")
next_day_df_predict = next_day_df_predict.reindex(columns=x_train.columns, fill_value=0)
prob_current = model_grid_search.predict_proba(next_day_df_predict)
next_day_df['leave_prob'] = prob_current[:,1]
The top 5 employees who have the highest probability to be absent in the next day are:
next_day_df.sort_values('leave_prob', ascending = False).head(5)
| index | Unnamed: 0 | employee | date | last_likes | last_dislikes | feedbackType | likes_till_date | dislikes_till_date | last_2_likes | last_2_dislikes | days_since_last_comment | last_vote | timezone | stillExists | no_of_days_since_first_vote | no_of_votes_till_date | perc_days_voted | avg_vote_till_date | avg_vote | last_2_votes_avg | prev_vote | days_since_last_vote | employee_joined_after_jun17 | countdown_to_last_day | reason | on_leave | no_leaves_till_date | previous_day_leave | last_2_days_leaves | weekday | month | week | leave_prob | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | 5445 | 33450 | 3WW | 2019-03-12 | 22.0 | 1.0 | CONGRATULATION | 22.0 | 1.0 | 22.0 | 1.0 | 331 | 4.0 | Europe/Madrid | 1.0 | 531 | 376.0 | 0.709434 | 2.151596 | 2.151596 | 4.0 | 4.0 | 1 | 1.0 | 999 | NaN | 0.0 | 1.0 | 0.0 | 0.0 | Tuesday | Mar | 12 | 0.000477 |
| 36 | 23024 | 20195 | aQJ | 2019-03-12 | 8.0 | 8.0 | INFORMATION | 237.0 | 71.0 | 56.0 | 10.0 | 190 | 3.0 | Europe/Madrid | 1.0 | 489 | 139.0 | 0.446945 | 3.071942 | 3.071942 | 3.0 | 0.0 | 178 | 1.0 | 999 | NaN | 0.0 | 14.0 | 0.0 | 0.0 | Tuesday | Mar | 12 | 0.000441 |
| 20 | 13726 | 10313 | DNY | 2019-03-12 | 0.0 | 0.0 | OTHER | 0.0 | 0.0 | 0.0 | 0.0 | 13 | 3.0 | Europe/Madrid | 1.0 | 678 | 236.0 | 0.351190 | 2.936441 | 2.936441 | 3.0 | 0.0 | 5 | 0.0 | 999 | NaN | 0.0 | 2.0 | 0.0 | 0.0 | Tuesday | Mar | 12 | 0.000422 |
| 12 | 8421 | 9018 | 6lL | 2019-03-12 | 1.0 | 0.0 | OTHER | 152.0 | 68.0 | 5.0 | 1.0 | 436 | 3.0 | Europe/Madrid | 1.0 | 676 | 194.0 | 0.294833 | 3.242268 | 3.242268 | 3.0 | 0.0 | 17 | 0.0 | 999 | NaN | 0.0 | 53.0 | 0.0 | 0.0 | Tuesday | Mar | 12 | 0.000414 |
| 32 | 20505 | 19706 | YDm | 2019-03-12 | 19.0 | 0.0 | CONGRATULATION | 523.0 | 250.0 | 34.0 | 9.0 | 69 | 3.0 | Europe/Madrid | 1.0 | 678 | 550.0 | 0.812408 | 2.943636 | 2.943636 | 3.0 | 3.0 | 1 | 0.0 | 999 | NaN | 0.0 | 1.0 | 0.0 | 0.0 | Tuesday | Mar | 12 | 0.000395 |
Save Models¶
The last step is to save models for future deployment or run. Scikit-learn models are usually saved as pickle files.
import pickle
# Dump the trained model with Pickle
model_pkl_filename = 'classifier_employee_absenteeism.pkl'
# Open the file to save as pkl file
model_pkl = open(model_pkl_filename, 'wb')
pickle.dump(model_grid_search, model_pkl)
# Close the pickle instances
model_pkl.close()
References¶
- Scikit-learn documentation: link
- Satyam Kumar, How to tune multiple ML models with GridSearchCV at once?: link
- Notes and lectures, Machine Learning module, MSc Business analytics, Imperial College London, Class 2020-22
- Harsha A, Shaked A, Artem G, Tebogo M, Gokhan M: The workforce of the future Workforce Analytics
- Harsha A, Shaked A, Artem G, Tebogo M, Gokhan M: Predicting absenteeism Workforce Analytics
- Hyperopt: The Alternative Hyperparameter Optimization Technique You Need to Know link